
There’s a common saying: “A backup isn’t a backup until you’ve tested it.” The same is true whether it’s a simple database failover or an entire data center/cloud provider failover. You simply won’t know if it works if you don’t test it.
When it comes to disaster recovery testing, that can be an expensive, painful, and arduous process.
But it’s required by companies for a reason. And not just for disasters like hurricanes, flooding, or earthquakes. Even minor catastrophic failures, like a cloud provider going offline, can trigger your data recovery, rollover, and backup plans.
To help make it easier, Gremlin recently released Disaster Recovery Testing.
Gremlin’s Disaster Recovery Testing makes it easy and fast to test your disaster recovery plan by simultaneously simulating catastrophic failures across your entire company, organization, or team.
How to use Gremlin for disaster recovery testing
When approaching disaster recovery testing, start with methodical, regular testing, then layer company-wide testing on top to test full-scale catastrophic failures.
1. Set up services with test suites and get a baseline
The first step is to know how resilient your individual services and applications are to failures and outages. This is where test suites come in.
A test suite is a group of reliability tests that simulate failures. Passing a test validates resilience, while failing it shows where your service isn’t responding correctly. Gremlin comes with pre-built suites that cover the most common outage causes, including unavailable resources, traffic surges, failed dependencies, and more.
The first time you run a test suite, your service will receive a reliability score based on the results. Use this as your baseline for reliability metrics. It gives you a starting picture of what needs to be addressed before each service is ready for a full-scale disaster recovery test.
2. Run tests regularly on individual services
Now that you have a baseline, you can prioritize fixes and work them into your sprints.
Then, repeat the tests to verify the fixes. Keep following this cycle and testing regularly to build reliability. At Gremlin, we test every service once a week. Over time, reliability scores will climb slowly and steadily. You’ll also be able to show that key disaster recovery mechanisms, such as zone failover, work correctly.
Regular reliability tests let you uncover and address risks to your disaster recovery plan with minimal disruption.
3. Run a full-scale scenario with Disaster Recovery Testing
By this time, all of your individual services should have been tested against the exact same failure, and there shouldn’t be any huge surprises.
Normally, this kind of test is incredibly disruptive and time-consuming.
Thousands of engineer hours are spent as teams coordinate with data center or cloud providers, and hundreds of engineers from teams across the company sit on a single phone call during off-hours.
Gremlin’s Disaster Recovery Testing changes that.
From a central location, you can create failure conditions across an entire company, organization, or team simultaneously to accurately simulate a catastrophic failure.
If a service fails the test, it’s instantly halted and restored to its previous state to minimize impact. Meanwhile, tests will keep running for the services that haven’t failed until they’re all complete and all services have either passed or failed.
Disaster recovery tests should be run in production environments to accurately verify your disaster recovery plan. Gremlin is proven to safely inject faults into production environments. Integrated Health Checks actively monitor your systems during testing.
In fact, before it could be launched, our CEO, Kolton Andrus, insisted that we run a disaster recovery test in our own production environment. The test ran successfully, uncovered opportunities for improvements, and, most importantly, didn’t cause any disruptions. Our on-call engineer didn’t even get paged while the test was running.
4. Report compliance and results
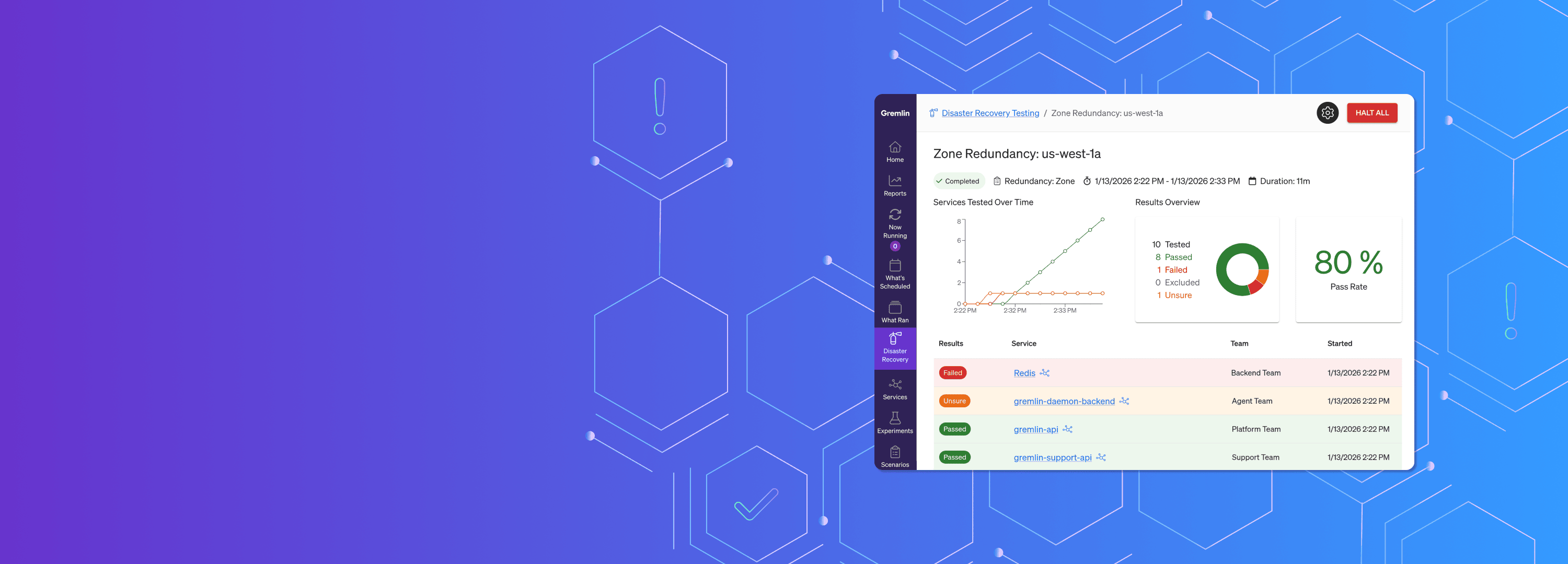
Once the test is complete, you’ll receive a comprehensive report showing the results, including a complete list of individual service results so you can drill down as needed.
Unlike traditional full-scale tests, which are costly and time-consuming to prepare, it’s easy to run the same Disaster Recovery Test again on Gremlin.
If any of your services fail and have issues they need to address, it’s a light lift to run the exact same test and verify fixes in the future. And you’ll get an auditable, trackable report showing that the risk was uncovered and addressed.
That same report can also be used for compliance and regulation reporting. It shows the test date, which test was run, the services tested, and the results. Instead of long, complicated checkboxes and surveys, compliance managers get clear data showing how disaster recovery standards were met.
How to run a disaster recovery region evacuation test
What does it actually look like to run a Disaster Recovery Test? Once you’re set up in Gremlin, running a Disaster Recovery Test in Gremlin can be done with just a few clicks. And the best way to see it for yourself is with this interactive demo that walks you through a region evacuation test.
By using Gremlin’s Disaster Recovery Testing, companies have already reported cutting their full-scale testing time by 90%.
And at a time when major outages seem to be happening more often, that protection is more important than ever.
Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALSchedule a time with a reliability expert to see how reliability management and Chaos Engineering can help improve the reliability, resilience, and availability of your systems.
Schedule now
Announcing Disaster Recovery Testing
Gremlin announces Disaster Recovery Testing for validating region failover processes, disaster recovery plans, incident response procedures, and more.

Gremlin announces Disaster Recovery Testing for validating region failover processes, disaster recovery plans, incident response procedures, and more.
Read more