
For many years, system uptime was the primary measure of reliability, especially when the most popular method of running software was on bare metal, on-premises servers. If a server was shutdown, rebooted, or otherwise became unavailable, downtime was expected until a system administrator could manually restart it. The introduction of virtualization in the early 2000s—followed by the rise of public cloud platforms—made it easier to automatically detect and reboot shutdown systems, but this didn't address the core problem of reliance on uptime. Applications were—and often still are—designed with the expectation that the underlying systems will have unlimited uptime, and this simply isn't realistic. We need to design our applications with the expectation that systems will shutdown, reboot, and fail suddenly due to power outages or other unexpected state changes.
In this blog, we'll take an in-depth look at the Shutdown attack and how you can use it to make your applications more resilient to system outages. We'll explain how it works, how you can apply it, and how it can help your team and organization build more reliable systems.
How does a Shutdown attack work?
If you're familiar with Chaos Monkey, then you already understand the basics of how a Shutdown attack works. The Shutdown attack issues a system call to shutdown or optionally reboot the operating system that the target is running on. For Linux hosts, it issues a reboot syscall, and for Windows hosts, it issues an ExitWindowsEx API call. In both cases, the attack performs a graceful shutdown to allow running processes to terminate cleanly. The exception is when targeting containers and Kubernetes Pods; in this case, the attack sends a <span class="code-class-custom">SIGKILL</span> command to terminate the container process(es) immediately.
The Shutdown attack supports these parameters:
- <span class="code-class-custom">Delay</span>: The number of minutes to wait before sending the shutdown command.
- <span class="code-class-custom">Reboot</span>: Whether to reboot the host after it shuts down. Note that Gremlin does not verify that the target system starts back up.
As with all Gremlin attacks, you can run a Shutdown attack on more than one target at a time. This is called the blast radius. Unlike other attacks, a Shutdown attack is fairly limited in its configuration. You can either shutdown or reboot the host, or delay the shutdown command by a set number of minutes.
When running your first Shutdown attack, start by targeting a single non-production host that you can easily restart manually if needed. A virtual machine, Docker container, or Kubernetes Pod is typically the best way to try out the attack in a safe and controlled environment. When starting the attack in the Gremlin web app, Gremlin displays a chart showing the state of your target system(s) as shown in the image below. We also recommend using a monitoring tool, observability tool, or connection testing tool to measure how long it takes the system to restart and become available again.
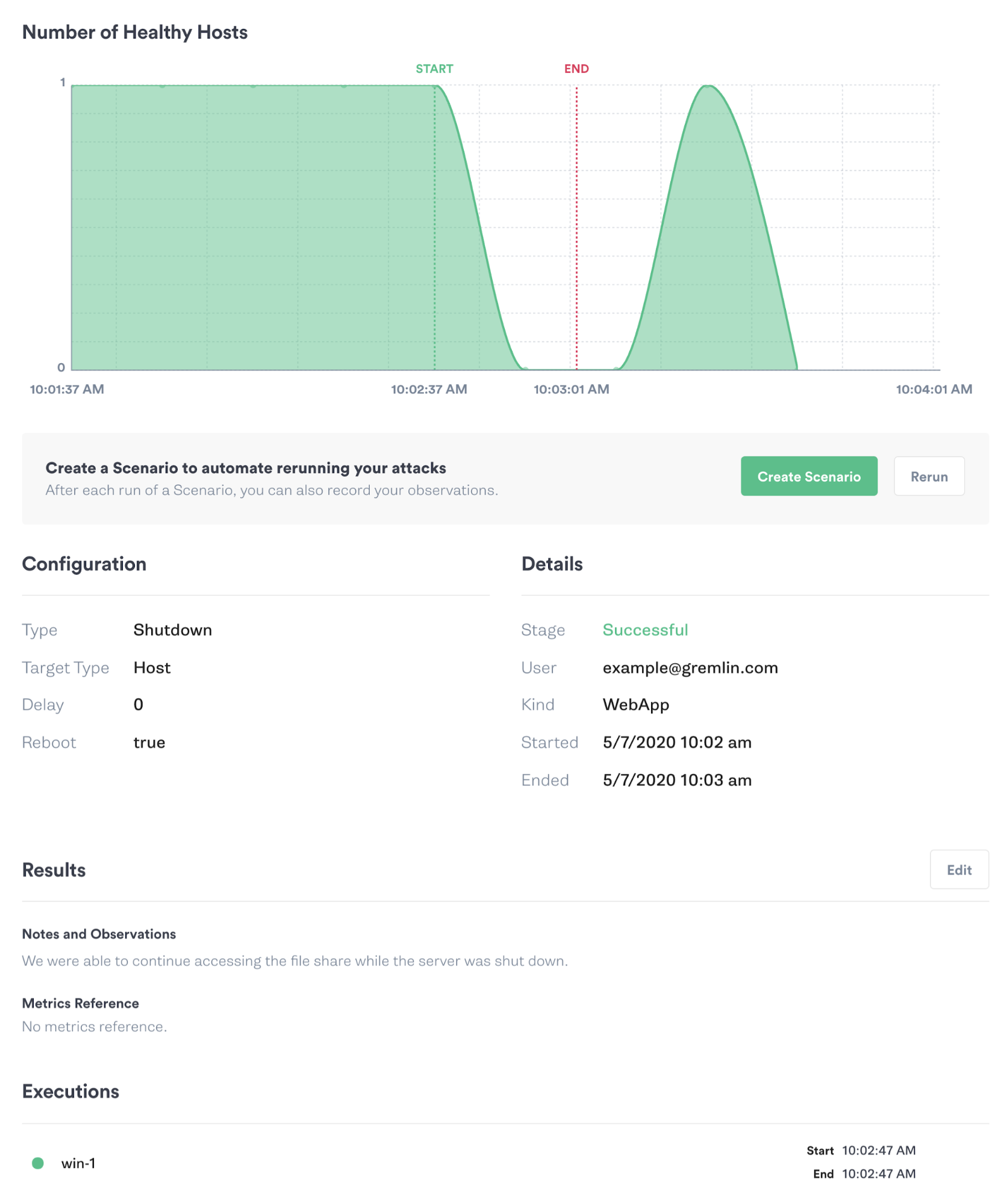
As you run these experiments, remember to record your observations, discuss the outcomes with your team, and track any changes or improvements made to your systems as a result. This way, you can demonstrate the value of the experiments you’ve run to your team and to the rest of the organization. Always remember to coordinate with teammates before running a Shutdown attack on systems that might impact their applications or services!
Why should you run Shutdown attacks?
Despite its simplicity, the Shutdown attack is an incredibly versatile and useful test of resiliency and recoverability. It's not just a test of whether a system can successfully reboot after a shutdown command, but when used on a virtual machine or public cloud system, it's also a test of whether the underlying platform can successfully detect and restart the shutdown system. This helps answer questions such as:
- What happens when a power outage or accidentally sent command causes the host to suddenly shutdown?
- If our cloud provider automatically scales back a virtual machine instance due to it being underutilized (or a Spot instance), do our applications keep running?
- If one of the primary nodes in our Kubernetes or Kafka cluster fails, does it result in a split-brain scenario?
- Can our clustered workloads successfully migrate or replicate to another node when one fails?
With Shutdown attacks, we can validate that:
- Our instances restart within a reasonable amount of time, and in the meantime, our workloads successfully migrate to healthy instances.
- Clusters that we've set up to be highly available remain operational, while load balancers automatically route traffic away from unhealthy nodes.
- We maximize the availability of our services by ensuring automatic replication and failover processes are functioning correctly.
Get started with Shutdown attacks
Now that you know how the Shutdown attack works, try running one yourself:
- Log into your Gremlin account (or sign up for a free trial).
- Create a new attack and select a host to target. Start with a single, easily recoverable host like a virtual machine instance.
- Under Choose a Gremlin, select the State category, then select Shutdown.
- Reduce the Delay to <span class="code-class-custom">0</span> to initiate the shutdown immediately after starting the attack.
- Optionally, uncheck Reboot to shutdown the system without restarting it.
- Click Unleash Gremlin to start the attack.
While the attack is running, be sure to monitor for the following outcomes:
- When I send a reboot command, does the system automatically restart as expected? If I'm using a cloud computing service and have automatic scaling or automatic restart policies in place, did those work as expected?
- Do all of my applications and services come up automatically when the system restarts? Did any of them fail to start?
- If this was a primary node in my Kubernetes or Kafka cluster, did the cluster maintain its integrity and operation after the node was terminated? If this was a worker node, were my workloads successfully migrated to a different node?
- Did my load balancer(s) reroute traffic from the shutdown node to a healthier node?
Once you've answered your initial hypothesis, try increasing the blast radius by targeting more hosts or containers simultaneously. You can use the Shutdown attack to create large-scale outages, such as an availability zone (AZ) or region outage. For example, entire data centers have been taken offline due to power outages, fires, and other unexpected scenarios. With a Shutdown attack, you can recreate this scenario, understand how your systems and services respond, and take steps to mitigate any failure modes that come up. This might mean replicating infrastructure, services, and data between two or more regions, and automatically failing over from one region to another in case of a major failure. As you implement these solutions, repeat the Shutdown attack to verify that your solutions work as intended.
Once you're comfortable running the attack, try running a Scenario. Scenarios allow you to run multiple attacks sequentially, as well as monitor the availability of the target system(s) using Status Checks. If you'd like guidance on where to start, try using one of our Recommended Scenarios. Gremlin includes several pre-built Shutdown Scenarios designed by our reliability experts for testing conditions such as service availability, host/Pod failure, and even helping train on-call teams. It's a quick and easy way to get started. Links to these Scenarios are available below.
This shutdown attack will make Gremlin force shutdown the host system. Your offering should gracefully exit when this happens, and restart when the system comes back up.
Length:
1 step
Attack Type
Shutdown
.svg)
Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALHow to troubleshoot unschedulable Pods in Kubernetes
Kubernetes is built to scale, and with managed Kubernetes services, you can deploy a Pod without having to worry...
.webp)

Kubernetes is built to scale, and with managed Kubernetes services, you can deploy a Pod without having to worry...
Read moreHow to fix Kubernetes init container errors
One of the most frustrating moments as a Kubernetes developer is when you go to launch your pod, but it fails to start…

One of the most frustrating moments as a Kubernetes developer is when you go to launch your pod, but it fails to start…
Read more