
On November 18, 2025, X, ChatGPT, Shopify, and many other major sites went offline simultaneously. Even Downdetector, Ookla’s popular outage tracking website, briefly went offline. What caused this issue? Why were so many major websites affected by it? And what steps can you take to reduce the impact on your own applications?
The configuration change that rippled across the Internet
At the heart of this outage is a simple configuration change. Cloudflare’s Matthew Prince goes into extensive detail in his post-mortem, but in short, Cloudflare engineers implemented a change that caused a configuration file to double in size. This configuration file is used by their Bot Management system, which analyzes all requests traversing the Cloudflare network for bot traffic. Among other things, this helps Cloudflare and its customers distinguish between requests from bots and those from humans.
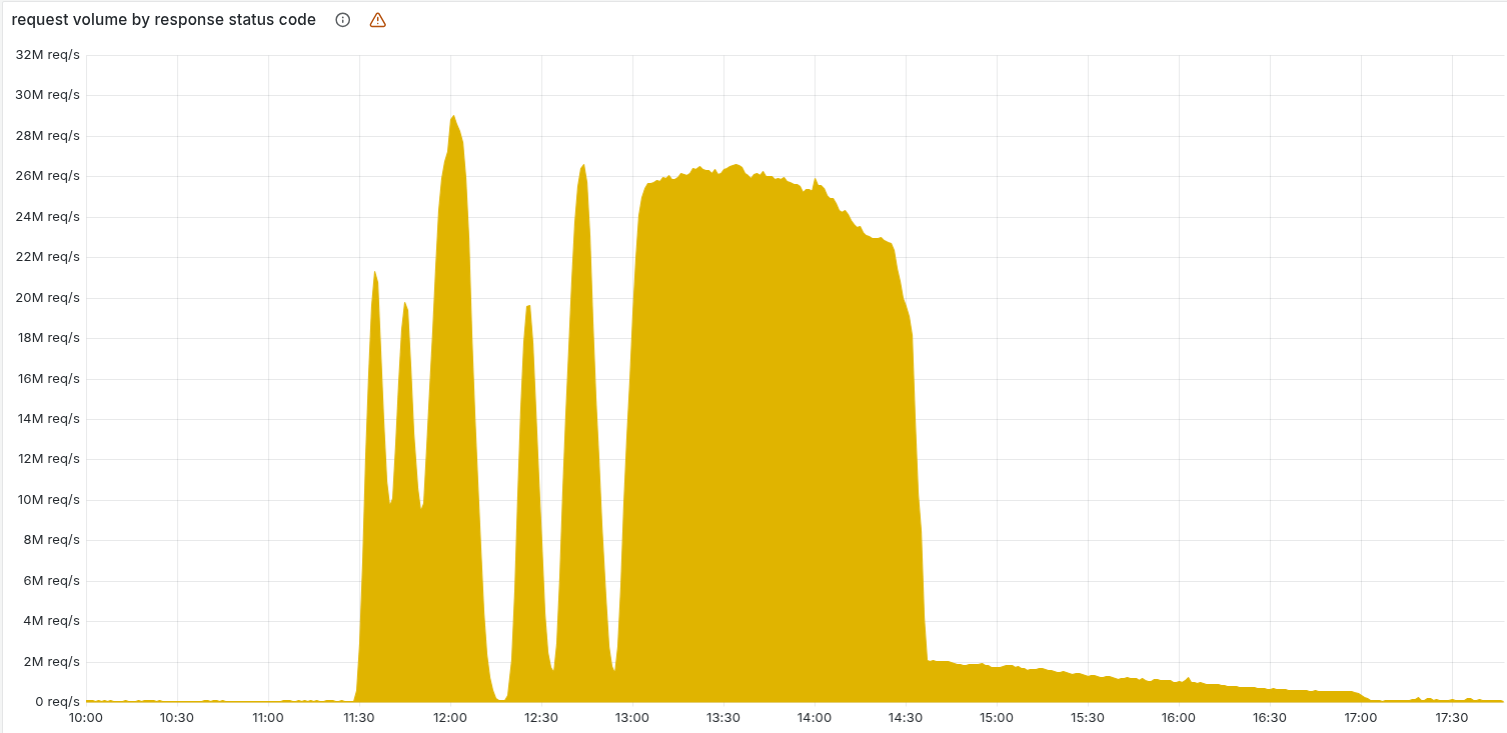
The problem is that Bot Management has an upper limit on the size of its configuration file. The new file became too large, which caused Bot Management to error and return HTTP 5XX error codes. The effect wasn’t immediate, though. The file took some time to propagate throughout their network, resulting in spikes in error rates that lasted only a few minutes each. It took around 90 minutes for the bad configuration to propagate fully and create a sustained high error rate.
This issue had a knock-on effect on other Cloudflare services, including Workers KV, Access, Turnstile, and the Dashboard. Because many of these services are dependent on each other (Workers KV is used for Access, Turnstile is used for Dashboard, etc.), a single failure in any one can have a cascading effect on the others. This is how a relatively small error in one service became an Internet-spanning outage.
If your system sees a small error and then it crashes or it blows up in some way, it can just keep cascading, and the error just propagates through the system. It just gets worse and worse. So a small error gets magnified into a bigger error…and you've basically got a runaway cascading overload.
Adrian Cockroft, “Chaos Engineering - What it is, and where it’s going”
To make matters more confusing, Cloudflare’s status page also went offline around the same time, although this ended up being a coincidence. Hats off to Cloudflare’s engineers for working through what must have been an extraordinarily stressful and confusing situation.
How can you prevent a similar situation from happening to you?
Cloudflare’s outage, while unique, has the signature of a classic cascading failure. When Cloudflare deployed the bad configuration file, only a subset of their systems picked it up, resulting in distinct error spikes. It wasn’t until the bad file was fully deployed to all systems that the error rate became steady.
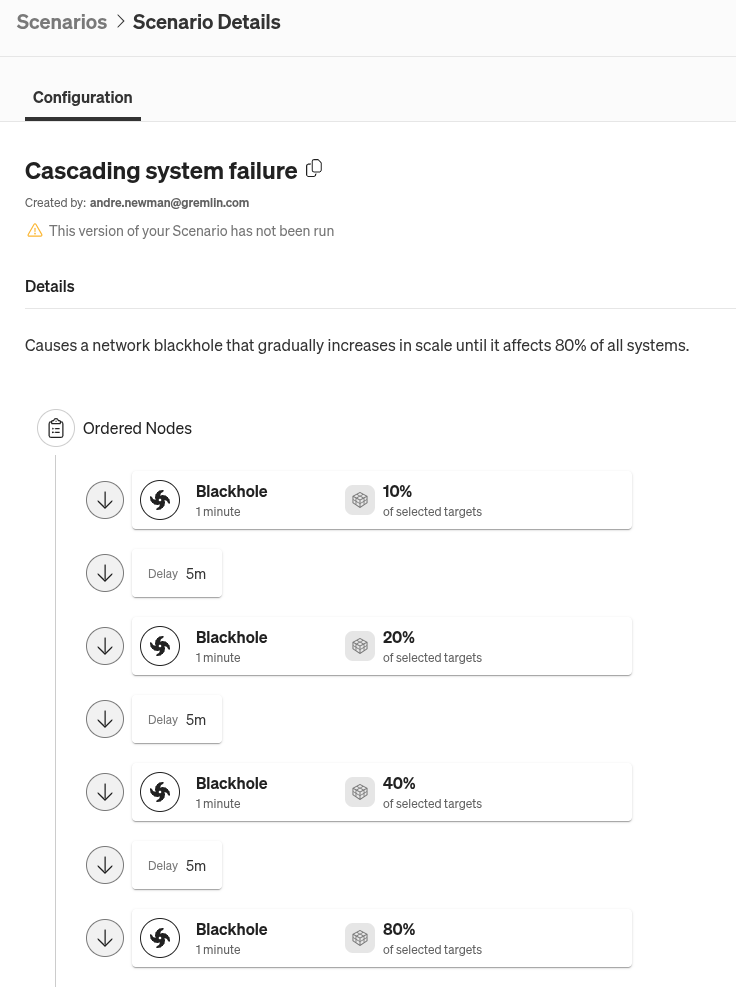
So, we have a critical system failure that gradually propogated to more systems over time. This is something we can replicate in Gremlin using a Scenario, which is a sequence of fault injection experiments meant precisely to replicate incidents like this. Instead of using a faulty configuration file, we can use a blackhole experiment, which drops network traffic to and from targeted systems (although it’s not a perfect 1:1 reproduction, the effect is similar). We can reproduce the cascading effect by spacing out each experiment by a few minutes, gradually increasing the blast radius (the number of systems impacted) for each one.
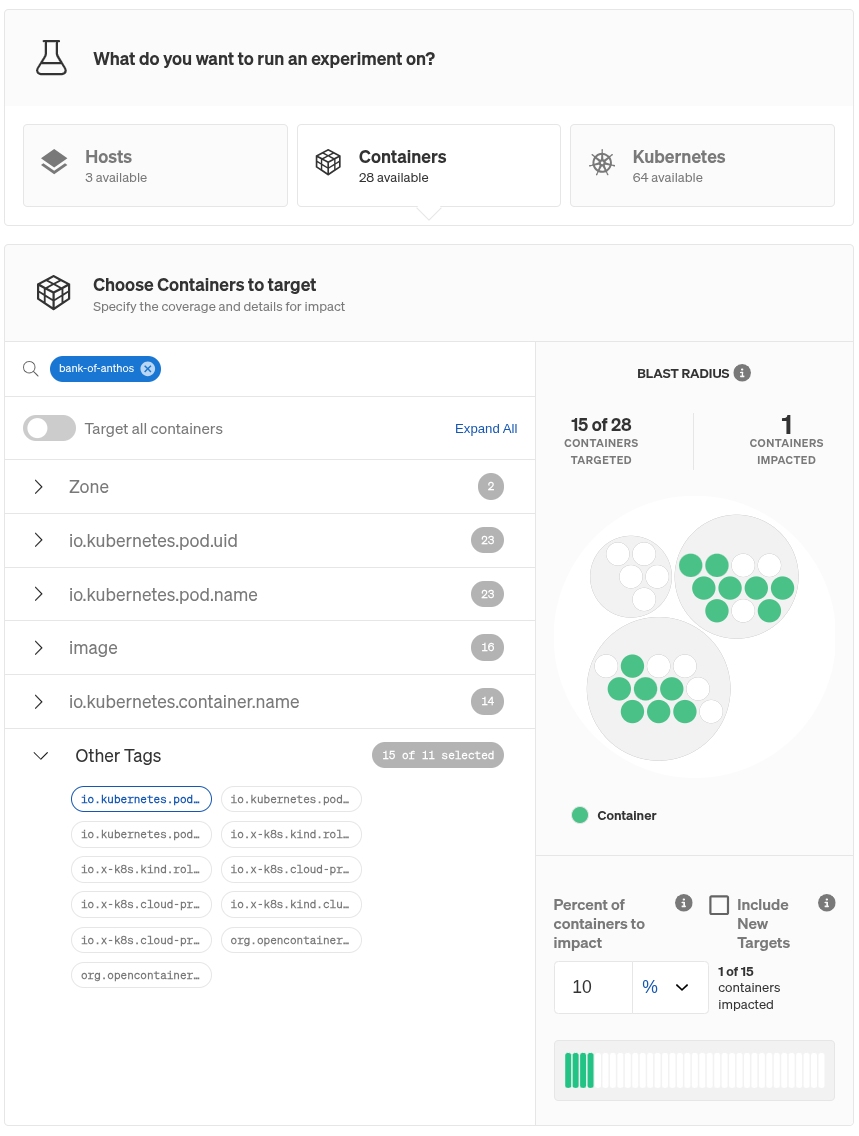
It’s important to remember that Cloudflare’s outage was caused by a failure in a specific service. In Gremlin, you can use service tags to identify which service your systems, containers, and Kubernetes resources belong to. When defining your experiment, Scenario, or reliability test, you can use these tags as selection criteria and limit the scope of the experiment to that specific service.
While the Scenario runs, use Health Checks to monitor your critical business metrics. Health Checks detect when the Scenario causes your metrics to exceed their thresholds. If they do, they will stop the Scenario, return your systems to normal, and flag the Scenario run as “failed,” meaning your systems aren’t resilient against this type of failure. If this happens, consider adding additional failover or error detection mechanisms to services that depend on this service, so a similar failure in production doesn’t take your entire application down.
Test your dependencies on external providers
What if you’re a Cloudflare customer and want to ensure your systems can stay up in case an outage like this happens again? In this case, you can use Gremlin’s dependency tests. A dependency is any service that your service relies on, such as a database, SaaS, or cloud infrastructure provider. Gremlin’s Dependency Discovery feature detects each service’s dependencies automatically, which is helpful for both identifying known and unknown dependencies and understanding what happens when they become unhealthy. Gremlin comes with several built-in dependency tests:
- The failure test drops your service’s connection to the dependency.
- The latency test injects small amounts of latency into each packet sent to the dependency.
- The certificate expiry test checks the dependency’s TLS certificate chain for any certificates expiring within 30 days.
Depending on which Cloudflare service your service calls, you may have a dependency similar to the image below:

If so, all you need to do is click the Run button next to the test you want to run. Gremlin will run the test on your service, simulate the failure of the dependency, and monitor your service’s Health Checks to ensure it remains available and responsive. If the Health Check detects a problem, it will automatically halt the test and return your service to its normal operating state. Using the insights from the experiment and Reliability Intelligence, you can identify the critical dependencies in your services and create a plan for how to mitigate the impact of their failures.
Know your single points of failure
Sometimes you just can’t route around a dependency failure. When a dependency has no viable alternative, it becomes a single point of failure (SPoF). In Gremlin, you can mark these by editing the dependency and selecting Mark this dependency as a Single Point of Failure. This will exclude the dependency from automatic testing, though you can still use the Run buttons to run each test individually. Even just knowing that a dependency is a SPoF improves your reliability posture, since you can highlight it as a known risk in incident response plans and disaster recovery runbooks.

Regardless of which tests you run, any proactive effort will improve your reliability posture by helping you identify failure points, mark critical dependencies, and create a response plan. That way, even if a large provider like Cloudflare goes down, you’re already prepared and have already minimized the impact.
Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIAL
Reliability lessons from the 2025 AWS DynamoDB outage
In October 2025, Amazon DynamoDB had a massive outage that took down hundreds of systems. Find out what your team can do to minimize the impact of similar outages in the future.


In October 2025, Amazon DynamoDB had a massive outage that took down hundreds of systems. Find out what your team can do to minimize the impact of similar outages in the future.
Read moreReliability lessons from the 2025 Microsoft Azure Front Door outage
In October 2025, Microsoft Azure Front Door and Content Delivery Network suffered a global outage. Find out what your team can do to minimize the impact of similar outages in the future.

In October 2025, Microsoft Azure Front Door and Content Delivery Network suffered a global outage. Find out what your team can do to minimize the impact of similar outages in the future.
Read more