
“There’s nothing riskier you can do than not measure your risk.”
—Jeff Nickoloff, Gremlin Principal Engineer
Do you know the current reliability risk of your systems? Do you know right now how your services will react to common failures like a dependency going down?
Sadly, most organizations don’t have answers to these questions, relying on QA tests and the skill of their engineers to deploy code they assume won’t break. But this is a process problem, which means you can’t hire your way out of it.
On top of that, modern complex architectures and rapid delivery systems make it impossible for engineers to be completely sure of their service reliability. Fortunately, resilience testing and reliability metrics fill in the visibility gap. By performing regular resilience tests, teams can create ongoing records of the results, then use this to calculate the current risk they’re facing.
This is the idea behind Reliability Scores: a metric that provides a snapshot of your current reliability risks based on the results of running reliability tests.
It’s important to remember exactly what makes a reliability metric valid. The following three traits are crucial to make sure you’re measuring the right thing—and using the metric correctly.
1. Actionable without busywork
A metric is just data. By itself, it’s not going to do anything to improve your reliability. You have to be able to look at the metric, then use it to take action and create real results. Otherwise, spending the time generating the metric is just a bunch of busywork.
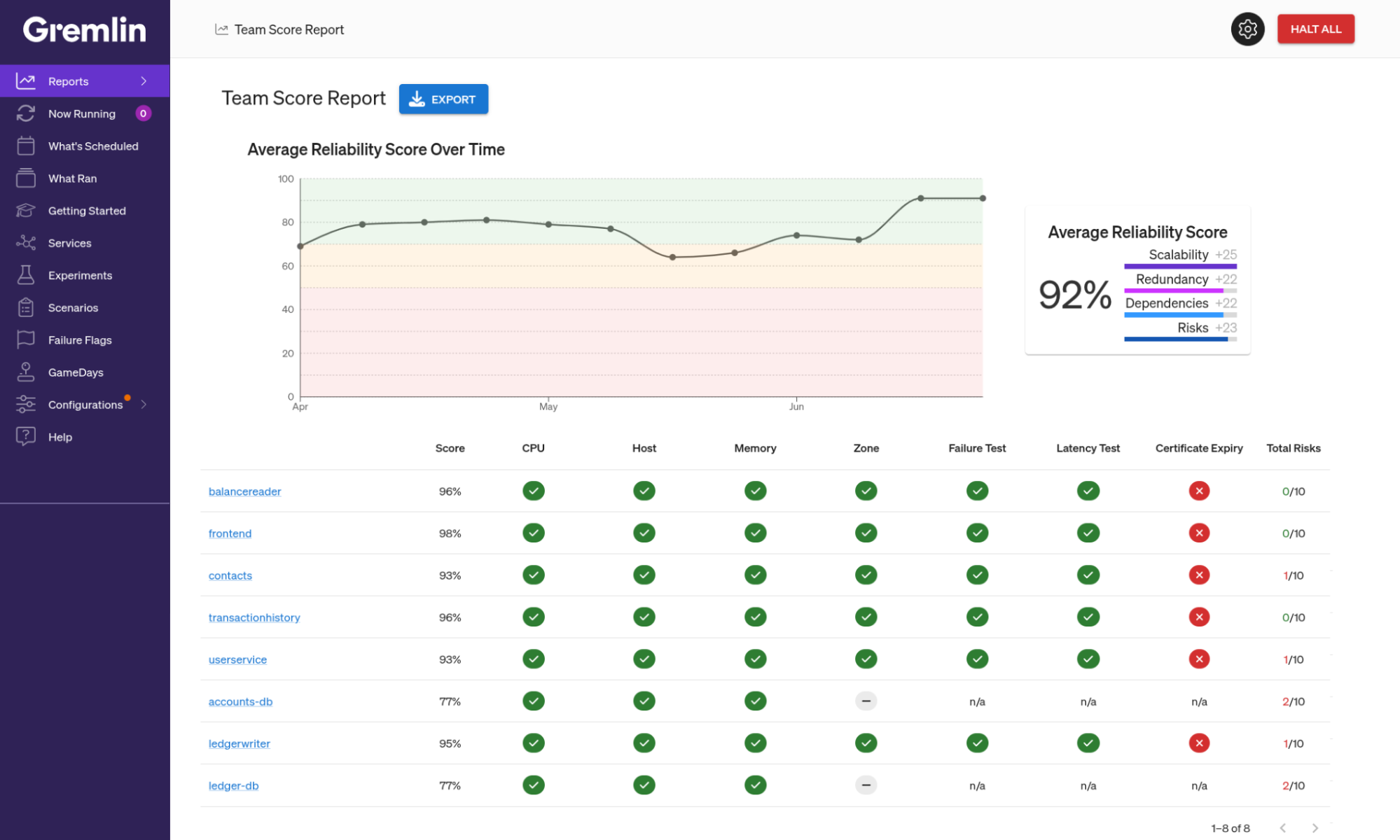
Your metric should be based on data that highlights specific risks so you can do something about them. That’s why our reliability score is based on aggregate test results. If the score goes down, then you can dig into the results, find the test that failed (or didn’t get run), and take action.
As a corollary, the metric should also be easy to generate so your teams don’t have the busywork of pulling it together every week. We recommend running standardized test suites weekly. The test results and score will be generated automatically for your team when you sit down for your regular reviews.
Which brings us to the next key factor and how your team should react to the metric.
2. Accountable without blame
We’ve all been there. You’re in a meeting reviewing metrics, and one of them went down. Suddenly everything becomes about blame and defending your actions. Meanwhile, the issue that caused the drop is still there, but people are too busy blaming others to actually do anything about it.
But there’s also the flip side where nobody owns a metric and there’s no one to do anything about it when it goes down. Neither of these outcomes will actually address issues and improve reliability.
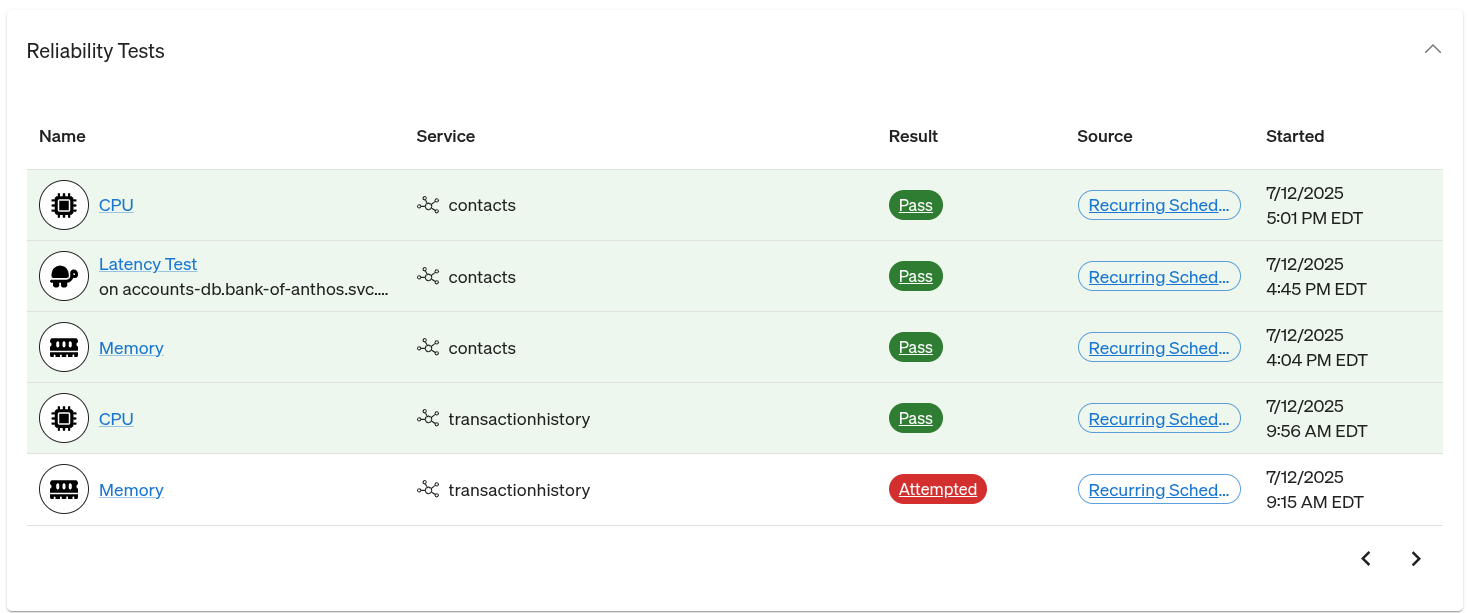
A good reliability metric finds a balance between the two with accountability. Rather than tie it to specific people, look at the service itself and how it interacts with everything around it. This is especially important in an era where code shipped by someone else can impact the reliability of your service. In situations like that, you need to focus on addressing the risk, not on “finding the culprit.”
By themselves, resilience tests hold no blame. They’re not a one-time grade that goes on your permanent record, but a living, changing measurement of risk. If the score goes down, all it means is that something changed and a risk was introduced. The service owners should dig in to address the new risk, whether it was introduced by them or not. Similarly, your testing history shouldn’t be used to determine “who caused what problem on this date,” but rather show how your reliability scores are improving over time.
The only way to improve reliability is by uncovering and mitigating risks, and that means holding teams accountable for addressing risks without making them so scared they want to hide risks. It’s essential that teams can trust the metric and the people and processes around it.
3. Accurate without noise
That metric trust is absolutely essential. If your reliability metric says your service is resilient to sudden spikes in traffic, then you need to be able to count on that result. You also need to have confidence in risk coverage, which is why your metric should be based on a spectrum of tests, automatic risk detection, and more.
Too many tests, too much process, and too much data can obscure risks. If your reliability metric requires every team member to craft a hundred different tests, then manually catalog every result in a spreadsheet with a sliding, weighted scale, then it becomes time prohibitive to perform. The tests will only be run partially and sporadically, and suddenly your metric is too variable to be useful.
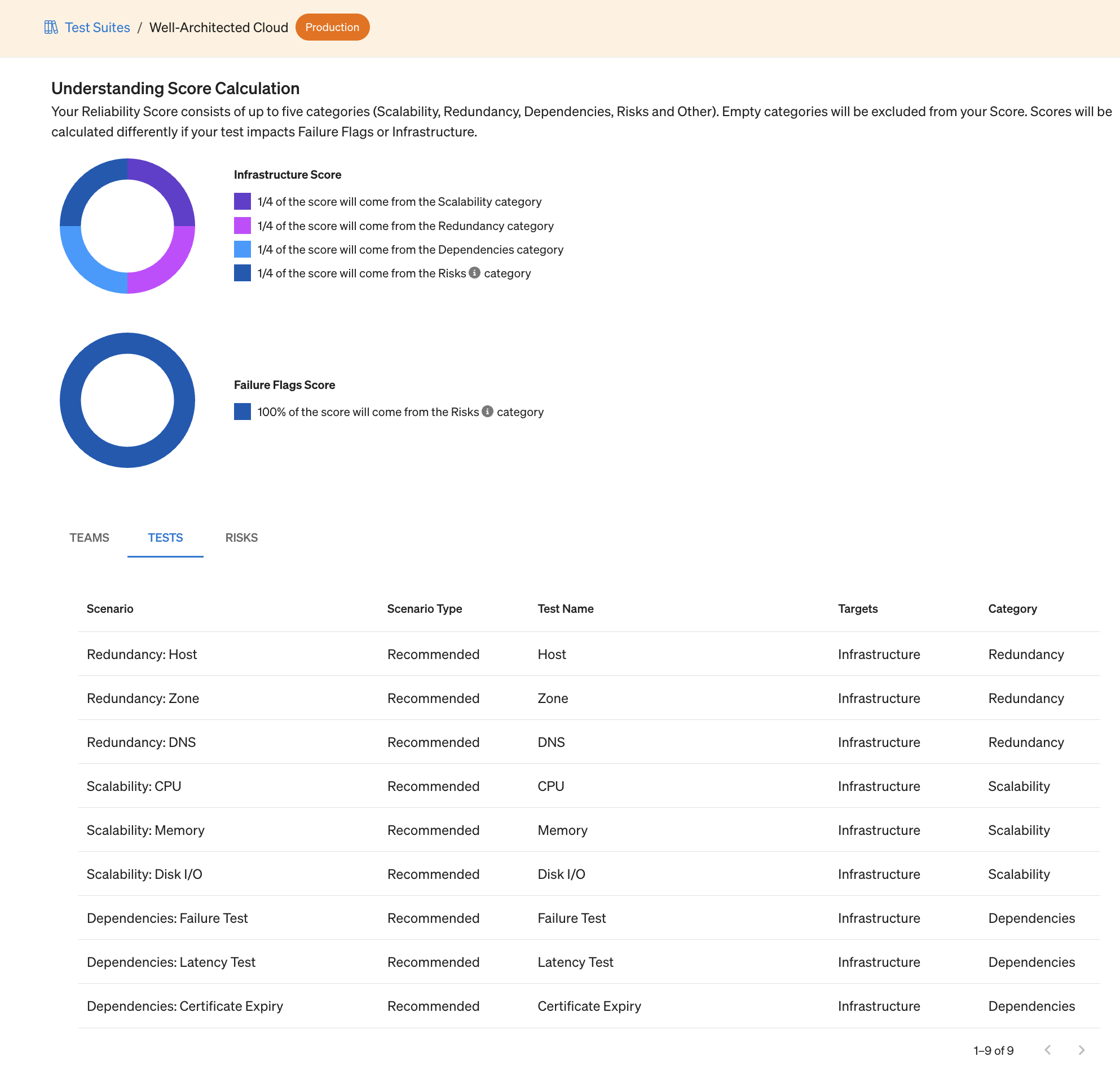
A reliability metric needs a standardized group of tests that is simple enough to be run on every service, every time. If you vary the standard set too much from service to service or test to test, then your metric is inconsistent. Your teams will be left guessing every time it goes up or down instead of using the shift to track down and address real risks.
Your reliability metric should improve reliability and make your life easier
The last time you want to find out about a reliability risk is when it causes a massive, customer-impacting outage that leaves teams scrambling to respond while the business loses money and the brand takes a hit.
The only way to systematically improve your reliability is to build the processes that proactively measure the risk and enable your teams to take action. Remember this whenever your team sits down to review reliability metrics. And if the score goes down, instead of blame, be glad that the risk was found now instead of when it caused an outage.
Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALSee Gremlin in action with our fully interactive, self-guided product tours.
Take the tour
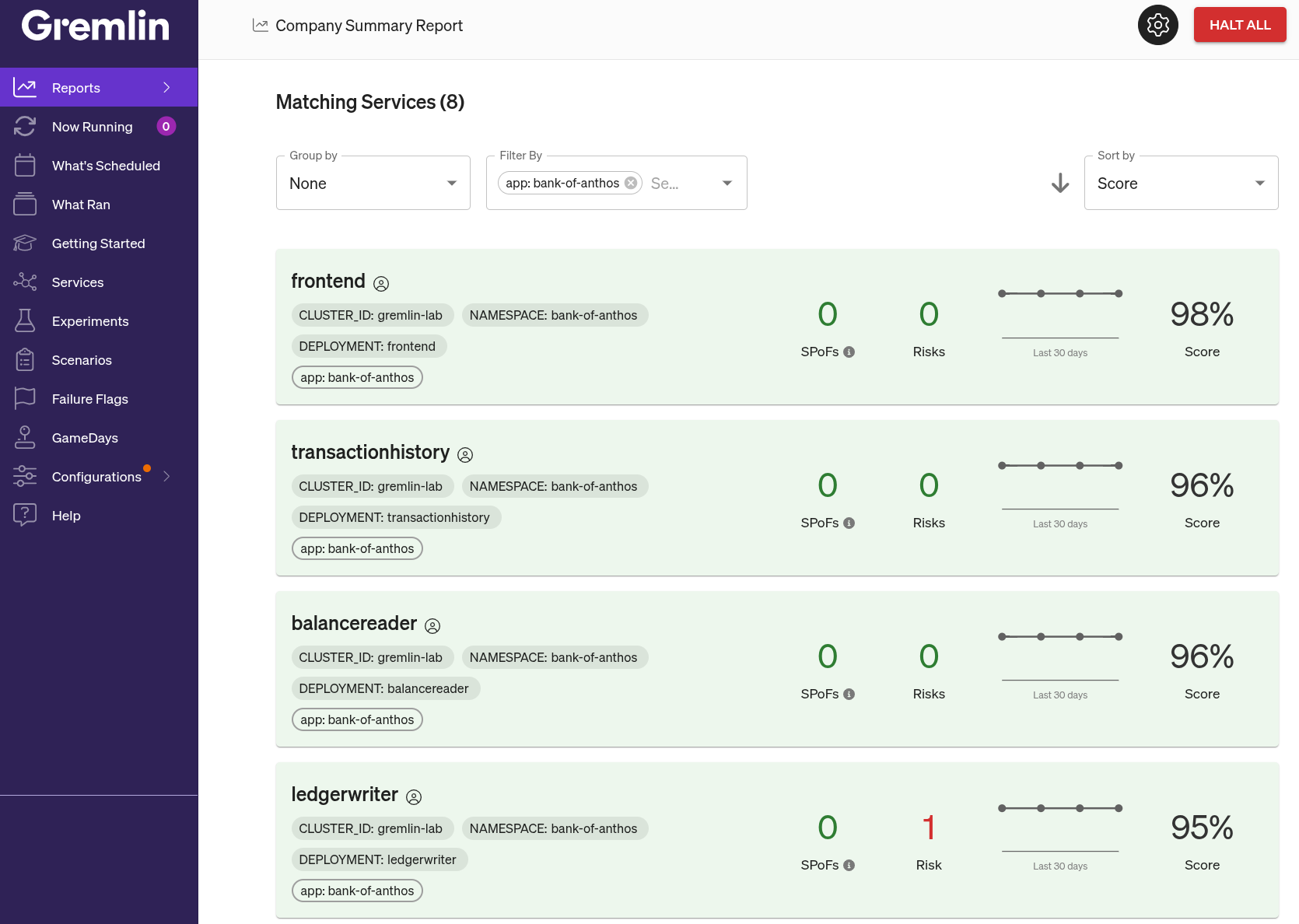
How Gremlin's reliability score works
In order to make reliability improvements tangible, there needs to be a way to quantify and track the reliability of systems and services in a meaningful way. This "reliability score" should indicate at a glance how likely a service is to withstand real-world causes of failure without having to wait for an incident to happen first. Gremlin's Reliability Score feature allows you to do just that.


In order to make reliability improvements tangible, there needs to be a way to quantify and track the reliability of systems and services in a meaningful way. This "reliability score" should indicate at a glance how likely a service is to withstand real-world causes of failure without having to wait for an incident to happen first. Gremlin's Reliability Score feature allows you to do just that.
Read more