
You’ve successfully run a Fault Injection test and uncovered a new failure mode before it impacted customers. And the failure could have taken down your whole system if it had happened in production.
Now what?
Since this is a potential P1 outage, you absolutely need to address the issue, but that’s going to take some time as you dig through the service to track down the problem.
Unfortunately, this is a common conflict. Once a test has failed, it can take deep knowledge of the code, service, and architecture to understand where to look. Even then, actually tracking down the issue can eat up hours. And as teams try to scale up reliability efforts, this time investment can become a barrier to adoption.
Not anymore.
Recommended Remediation, part of Reliability Intelligence, helps teams move faster by analyzing test results, then returning a list of the most likely culprits behind the failure along with recommendations for how to address the issue.
With Recommended Remediation, engineering teams get a built-in expert with each and every test to help them pinpoint issues and fix them faster, so they don’t have to choose between reliability and velocity.
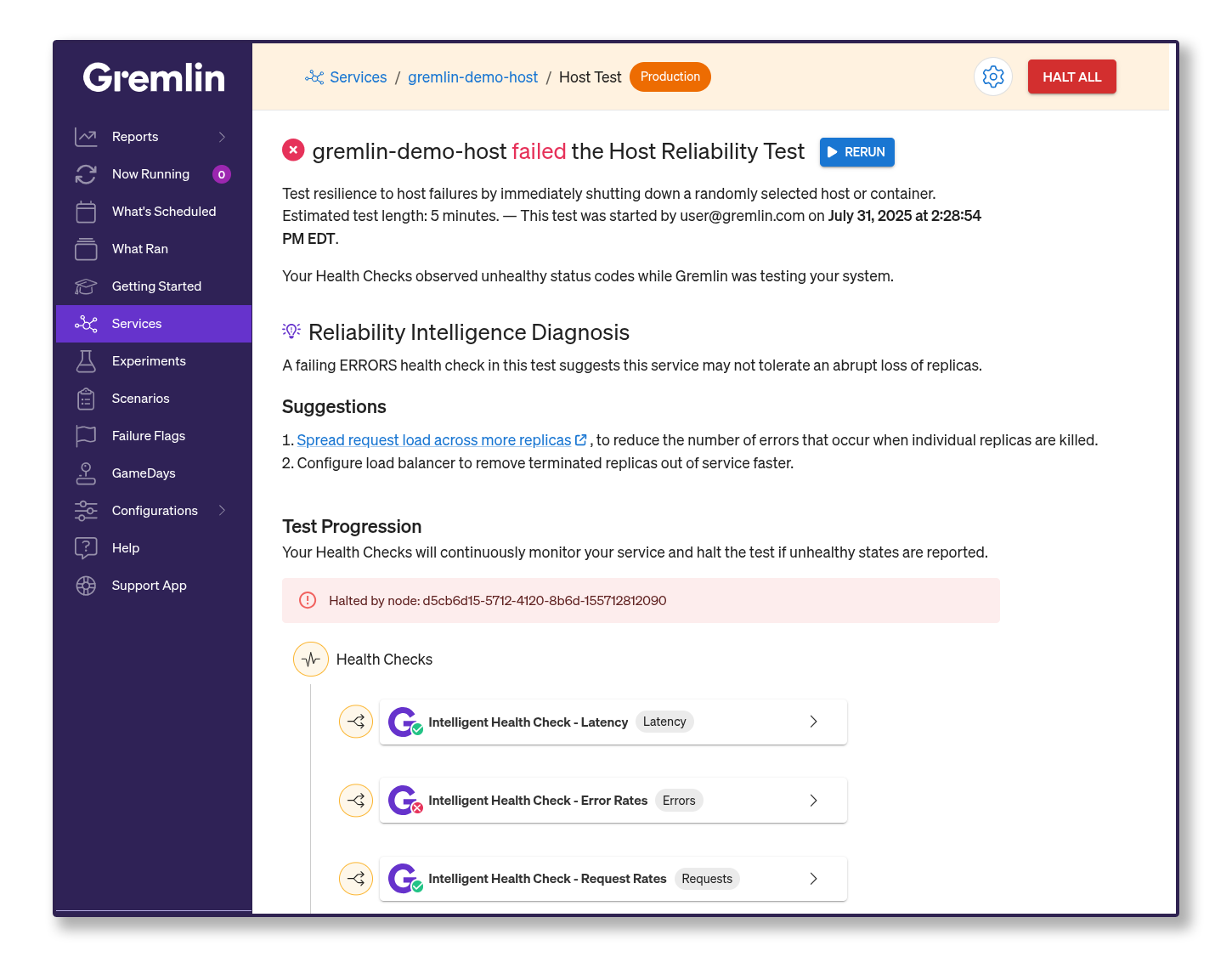
Part 1: Start with Experiment Analysis context
Recommended Remediation builds on Experiment Analysis, also part of Reliability Intelligence. Experiment analysis combines data from the type of test, metrics, health checks, and key events during the test to provide crucial context that connects the cause of the failure to the effect.
By combining several different types of data, Experiment Analysis determines a list of possible failure causes. These potential causes are the foundation for Recommended Remediation, and are correlated with possible recommendations based on the kind of test, the specific service in question, and more.
Part 2: Layering in reliability expertise
The Gremlin team has years of experience keeping critical uptime applications reliable, both as Chaos Engineering pioneers and as operations experts at companies like Netflix and Amazon. We’ve helped hundreds of companies, including global enterprises, achieve exacting performance and uptime requirements. Whenever our engineers sit down with our customers, the testing process goes faster and teams figure out how to address the root cause sooner.
We designed Recommended Remediation to give you access to that expertise with every test.
Every recommendation is specifically curated by our experts to follow patterns that we trust and stand behind. These recommendations are then selected based on your unique tests and environment, cross-referenced with best practices and common patterns.
Now, when a test fails and a reliability risk is uncovered, you’ll immediately get specific, actionable recommendations to help you address the risk.
We use recommendations to move faster and increase reliability
One of the reasons we can stand by our recommendations is that we’ve put them to the test. At Gremlin, we use our own product to improve the reliability of our platform. We test regularly and integrate test reviews into our production and sprint meetings. But even with our expertise and more mature reliability practice, Reliability Intelligence and Recommended Remediation helped us move faster by connecting the dots for us.
A recent example involved one of our single points of failure, or dependencies that will immediately cause problems if they become reachable. We regularly test these dependencies so we know how they fail, whether our health checks catch the issues, and to make sure our monitoring alerts us correctly if something goes wrong.
In this case, the single point of failure was a security token service. While developing Recommended Remediations, we ran a dependency failure test on it and, as expected, we received errors in our Datadog monitor. But instead of the alerts we expected, we got back latency alerts as downstream processes slowed to a crawl.
The test reset and everything returned to normal function, but we were left with a question: why did we get latency spikes when we expected error spikes?
Instantly, Recommended Remediations pointed us in the right direction. By comparing the type of test we ran (dependency unreachable) with the health checks and kind of errors (latency), it suggested tuning the dependency timeouts. As it turned out, our STS client in this context was using the Java SDK's default connection timeout of 10 seconds and a default read timeout of 50 seconds, both of which added too much latency. We tuned those appropriately, and the systems started performing as expected.
Throughout feature development, we also generated recommendations for prior issues where we already knew what the correct fix was. The suggestions were accurate and showed we were on the right track with a useful product feature.
Scale reliability testing across your organization
Recommended Remediation helps experienced teams move faster, but it also helps new teams get started. By providing teams with crucial context between the tests and their systems, it lowers the adoption barrier, making it easier to start testing and get results without having to invest the time to build up expertise.
The result? It’s now easier than ever to scale effective reliability efforts across your organization. All you have to do is set up standardized test suites, whether customized or using the built-in reliability test suites, set health checks, and you’re ready to go.
Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALSee Reliability Intelligence in action with the self-guided tour.
Take the tourReliability Intelligence: your reliability expert
Gremlin’s Reliability Intelligence combines Experiment Analysis, Recommended Remediation, and an MCP Server to help teams increase reliability faster than ever.


Gremlin’s Reliability Intelligence combines Experiment Analysis, Recommended Remediation, and an MCP Server to help teams increase reliability faster than ever.
Read more