
Chaos Engineering has proven itself to be incredibly effective at tracking down failure modes, remediating reliability issues, and preventing risks before they happen. Unfortunately, it can also come with a steep adoption curve. In order to get the most out of Fault Injection testing, a practitioner needs to have a deep knowledge of the service, its expected behavior, and the code behind it.
Ultimately, the rewards are worth the time. As you build momentum, the practice becomes more natural, the process gets smoother, and the results more fruitful. But that initial effort has limited adoption in many organizations, especially with engineering teams that already have high demands on their time.
Gremlin took a major step towards smoothing this adoption with Reliability Management, a combination of test suites, observability integrations via health checks, and reliability scores to make it easy to run a standard group of tests and determine whether a test passed or failed.
Experiment Analysis, part of Reliability Intelligence, lowers the adoption barrier even more by using machine learning analysis to provide crucial context beyond a simple pass/fail.
With a traditional Chaos Engineering experiment, you have to manually observe changes in system behavior, dig in to determine whether it was expected, and then determine why the behavior happened. Experiment Analysis shows you if a test passed or failed, then provides context for why it failed and possible causes, removing hours of manual effort.
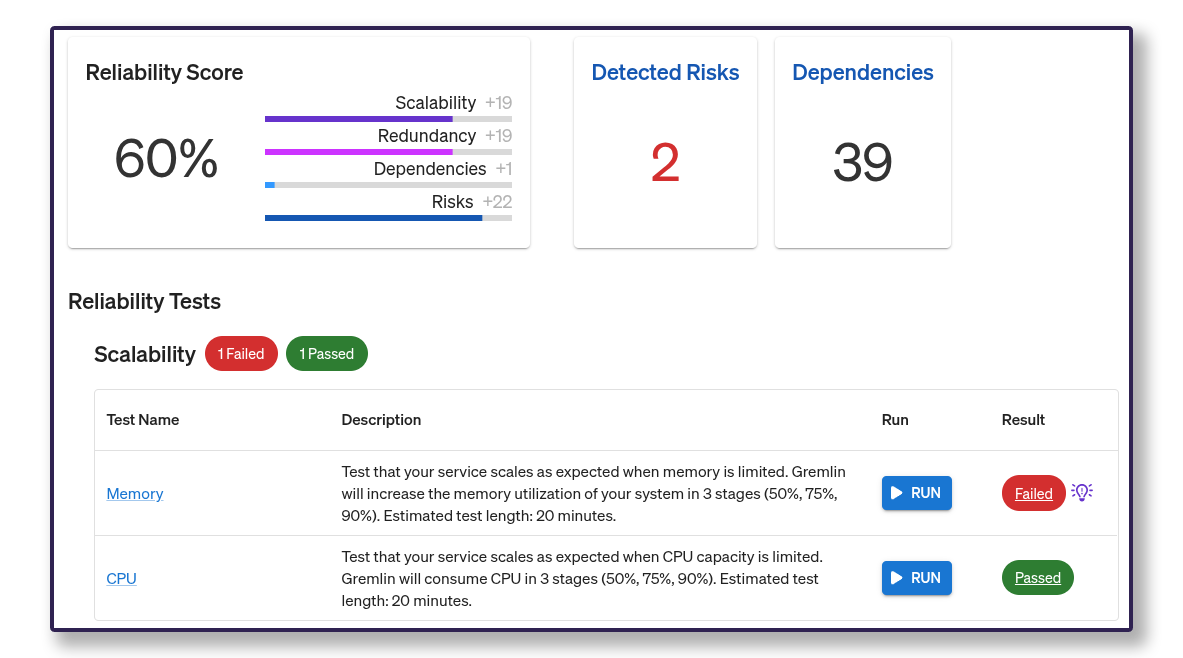
Using expected behavior to determine pass/fail
When running an experiment, you must define pass/fail parameters. Sometimes this is pretty straightforward, such as when a test results in a complete crash. But it’s not always that cut and dry. The key part is to define expected behavior, then use that to determine whether a test passed or failed.
Consider zone failover as an example. Many teams have redundant systems running in two or more availability zones. If one zone is unavailable, its services should fall back to the other zone. But what if the remaining zone falls over from the increased traffic? In this case, the failover did what it was supposed to, so technically this could be called a success. Except the whole service crashed, which is probably not expected behavior, so the test should be a failure
This is why it’s important to keep expected behavior as your pass/fail north star. Even if individual parts work correctly, we need to look at the whole service. This allows us to uncover failure modes in unexpected places, such as availability zones that aren’t correctly set up to handle the increased traffic from a zone failure.
Experiment Analysis starts with this same idea at the core. By predicting expected behavior based on key signals, it can determine if a test failed or not, then draw correlations from the effect back to the cause of the issue, even if it’s from an unexpected source.
Manual digging and testing don’t scale
In the early days of Chaos Engineering, a lot of time and effort was spent building out specific tests and pass/fail parameters, then interpreting the results. As a result, testing was often confined to experienced SRE or testing teams, more out of necessity than organizational preference.
Scenarios, health checks, and Reliability Management test suites were designed to streamline this process and make it easier to scale testing across the organization to individual teams. These allow you to set specific test scenarios with distinct pass/fail criteria, monitor system behavior during the test, and then run the same group of tests on a regular basis.
Gremlin customers across industries and maturity levels have already achieved great results rolling standardized test suites out among engineering teams and enabling them to run their own tests. However, a failed test could still cause a process bottleneck by requiring cycles to dig in and figure out what could have caused the issue.
That’s where Experiment Analysis comes in. Now you can not only flag that there was a deviation from expected behavior, you can also get pointed towards the most likely causes of the deviation, saving time and allowing teams to move faster.
This is true even with experienced teams. At Gremlin, we use our own product as part of our reliability efforts, and that includes Experiment Analysis. We’re already using it in our regular review meetings to get to root causes faster and spend less time resolving issues. In fact, one of the ways we knew we were on the right track with Experiment Analysis and Recommended Remediation was when it started suggesting fixes for problems we already knew we needed to address
How Experiment Analysis tracks down the root cause
Experiment Analysis finds correlations between your monitoring data, health checks, test types, and events that occurred during the test, such as Out of Memory events.
The first step is to classify your Gremlin health check into one of three categories: ERRORS, LATENCY, or REQUEST RATE. Knowing the type of signal this health check is monitoring points your analysis in the right direction. (And if your health checks are an issue, then Gremlin can detect this and give you recommendations for defining good health checks.)
From there, the analysis layers in additional classification based on your specific reliability tests. For example, is it a test that makes a dependency unavailable? Is it a test that adds latency to a zone? Data like this relates specifically to the type of failure being introduced.
These two categorizations are then combined with behavior and events that occurred during the test. By analyzing the three together, Experiment Analysis identifies possible cause-effect relationships between the impact created by the test and any health or performance changes of the target service.
Next step: turn cause into actionable remediation
Before Reliability Intelligence, this analysis would have been done manually by an experienced engineer looking over the results. Experiment Analysis makes the connections for you, so you can run a test and figure out what to address faster. This reduces toil, smooths out the adoption curve, and helps teams build momentum faster.
This is only the first step. Experiment Analysis goes hand in hand with Recommended Remediation, which takes the results and creates tailored, actionable recommendations. We’ll dig into the recommendations more in another blog.
Ready to see the analysis in action for yourself? Check out our Reliability Intelligence product tour!
Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALSee Reliability Intelligence in action with the self-guided tour.
Take the tourReliability Intelligence: your reliability expert
Gremlin’s Reliability Intelligence combines Experiment Analysis, Recommended Remediation, and an MCP Server to help teams increase reliability faster than ever.


Gremlin’s Reliability Intelligence combines Experiment Analysis, Recommended Remediation, and an MCP Server to help teams increase reliability faster than ever.
Read more