
The concept of Chaos Engineering is most often applied to backend systems, but for teams building websites and web applications, this is only half of the story. While it’s important to maintain reliable backend infrastructure and applications, there’s a lot that can go wrong even after we’ve fulfilled the user’s request. Web pages can load slowly, images and scripts might fail to download, and large geographic distances can add significant latency. These can have a big impact on the user experience and can happen even when our backend systems are working perfectly.
In this blog post, we’ll present a slightly different approach to Chaos Engineering by injecting it into client-side applications, specifically websites. We’ll point out some of the failure modes unique to websites, run chaos experiments using Gremlin, and even show how to automate experiments alongside client-side testing tools.
What is client-side Chaos Engineering?
With client-server applications, there’s more to reliability than just keeping our backend up and running. Since some of the processing takes place on the user’s device, we need to consider the many potential failure points that can occur after data leaves our systems. It doesn’t matter if our web server has five nines of uptime if the website doesn’t load properly; users will attribute the failure to us regardless.
For example, Cloudflare, a major proxying service and content delivery network provider, experienced a recent outage that impacted websites including Medium, GitLab, Discord, and Downdetector. Even if these websites’ backend systems were fully operational, the dependency on Cloudflare made them appear offline to their users. Problems like these can’t always be accounted for when running chaos experiments on the backend, which is why we need to consider client-side experimentation.
However, running chaos experiments on clients isn’t as straightforward as it is for backend infrastructure for many reasons:
- We have almost no access to or visibility into client systems.
- We can’t install Chaos Engineering tools, collect system-level metrics, or map out client systems.
- Many client applications—like browsers—are deliberately sandboxed to prevent the system-level control needed for running infrastructure-level attacks. Even if they weren’t, attacking a user’s system without their knowledge or permission would be a huge breach of trust.
Instead, we can run chaos experiments on a test system that we control. We can install Gremlin onto this system, run attacks, interact with our website as if we were a user, and observe the behaviors without impacting real users or backend systems. This doesn’t need to be a powerful system either; it can be a developer’s workstation, lightweight virtual machine, or any other system that can connect to your test environment. We can run a full range of experiments on this system to simulate real-world conditions such as low-bandwidth or high-latency connections, third-party hosting outages, DNS errors, and more.
However, this creates an additional challenge. To measure the impact that a failure has on the user experience, we need a way to consistently perform user actions. For example, if we increase latency by 500 ms, how much longer does it take for a user to log in to our application? Fortunately, we can leverage a solution that’s already widely used for client-side testing: browser automation. Browser automation tools like Selenium let us code actions like mouse movements, key presses, and page navigation. This is perfect for automating functional and usability tests, and by pairing it with Chaos Engineering, we can add reliability testing to our suite of automated browser tests.
To demonstrate how this works, we’ll create a Java application that uses Selenium WebDriver for browser automation, and the Gremlin REST API to initiate attacks. We’ll run these on our test system, record the duration of each test, and mark the test as successful if Selenium can complete its actions without exceeding a ten-second timeout period.
Experiment 1: CDN/cache failures
Content delivery networks (CDNs) are commonly used to host resources such as images, JavaScript files, and CSS. The average web page is nearly 2 MB in size, and offloading heavy resources to third-parties is extremely effective for reducing backend server traffic and latency. However, this makes each CDN an additional point of failure for every site that relies on it. If the CDN fails, its customers could also fail.
Our first client-side experiment is to test whether our website works even when our CDN is offline. To test this, we’ll use a blackhole attack to drop all network traffic between our test system and our CDN. Assume that we host all of our images with the fictional company DemoCDN and that our assets are served from the domain “assets.democdn.com”. Our pass/fail criteria will be whether an image on our home page loads successfully.
We want to make this experiment repeatable so that we can run it alongside our automated frontend tests. To do that, we’ll construct a Gremlin REST API call to initiate the blackhole attack. We’ll add our test system as the target (named “selenium-server”) and only target traffic to and from “assets.democdn.com”. We’ll run this attack for ten seconds, which coincides with the timeout period we set for Selenium:
To check the image’s load state, we’ll use Selenium’s JavascriptExecutor interface to retrieve the image’s <a href="https://developer.mozilla.org/en-US/docs/Web/API/HTMLImageElement/complete"><span class="code-class-custom">HTMLImageElement.complete</span></a> attribute. This attribute returns true if the image has finished loaded, and false if it hasn’t. Here is our test case written in Java:
As expected, the image never loads due to the blackhole attack, and so we exceed the ten-second timeout. We can confirm this by loading the website in a browser and using the JavaScript console to check the image’s load state:
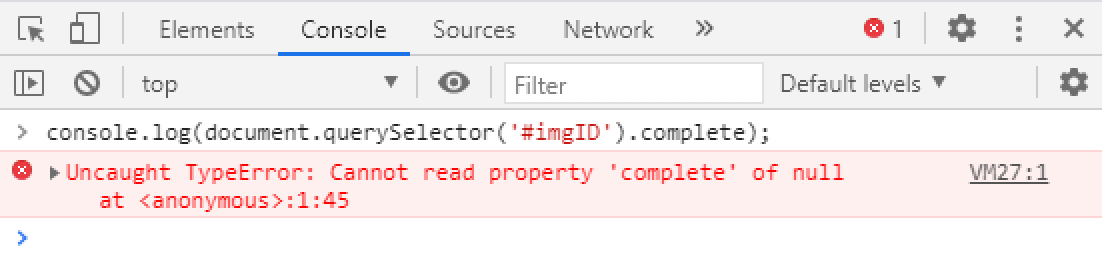
What this tells us is that if our CDN ever goes down, visitors will see our website without any images. Hardly an ideal user experience.
To address this, we could use a library like Fallback.js or RequireJS to set a fallback URL for each image in case the original URL is unavailable. We could set this fallback to our backend servers, and while this would significantly increase our network traffic during a CDN outage, it would allow our page to load successfully until the CDN came back online. After we implement the fix, we can simply re-run the test case to verify that the site loads correctly.
Experiment 2: optimizing for performance and usability
Not every user has access to unlimited high-speed Internet or fast devices. Complex, media-rich websites are visually appealing and engaging, but are also painful to use for users on slow connections, data-capped accounts, or lower-end devices. Using Chaos Engineering, we can simulate these conditions, use browser automation to test our website’s loading speed and usability, and use our observations to implement optimizations.
For example, we’d expect that users located geographically far away from our backend servers or CDN will experience higher latencies. A user in California might load our page instantly, but a user in Australia might have to wait an extra 200-400 ms. To replicate this experience, we can use a latency Gremlin to add 400 ms of latency to network calls between our backend servers (or CDN) and the test system. We can then use Selenium to measure the amount of time it takes to complete a certain workflow, such as logging in.
Here’s our Gremlin REST API call:
And here’s our test case (assume we’ve already initialized WebDriver and initiated the experiment):
We can run this test twice: once with an active latency attack, and once without. If the difference is significant, we should look into ways of optimizing our website for our Australian users. This might involve:
- Using caching and CDNs to move heavy, static content closer to those users.
- Migrating from HTTP/1.1 to HTTP/2 or HTTP/3.
- Reducing upfront page weight by optimizing images or using lazy loading.
Avoiding any JavaScript that blocks the DOM or delays assets from downloading so users can interact with the site faster.
Conclusion
We can’t control everything that happens on our user’s devices, but we can build our websites to render as reliably as possible. Automating chaos experiments and browser testing helps us protect against situations such as third-party dependency failures and external outages so that we can continue to serve users. By using the Gremlin REST API to automate our chaos experiments, we can continually test for reliability whenever we run our frontend tests for continuous chaos.
If you’re ready to add Chaos Engineering to your client-side tests, you can easily convert existing attacks into API calls by opening the attack or Scenario in the Gremlin web app and clicking “Gremlin API Examples” in the bottom-right corner of the screen. You can learn more about creating and running API calls in our API reference documentation.

Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALWhat is Failure Flags? Build testable, reliable software—without touching infrastructure
Building provably reliable systems means building testable systems. Testing for failure conditions is the only way to...


Building provably reliable systems means building testable systems. Testing for failure conditions is the only way to...
Read moreIntroducing Custom Reliability Test Suites, Scoring and Dashboards
Last year, we released Reliability Management, a combination of pre-built reliability tests and scoring to give you a consistent way to define, test, and measure progress toward reliability standards across your organization.

Last year, we released Reliability Management, a combination of pre-built reliability tests and scoring to give you a consistent way to define, test, and measure progress toward reliability standards across your organization.
Read more