Artificial intelligence recently took a major leap from “saying” to “doing.” Instead of simple back-and-forth chats, we’re now allowing automated AI processes to take action on our behalf—from responding to emails to building and deploying complete applications. This shift from “assistant” to “actor” can make applications more capable, but it also creates additional failure modes.
We’ve discussed AI reliability risks before, and while many of the same risks apply to agentic AI, they can manifest in different ways. We’ll look at three in particular: network interactions, non-deterministic behavior, and third-party dependency complexity. We’ll examine each of these risks, how they’ve changed with agentic AI, and how you can use proactive reliability testing to ensure your AI workloads are resilient.
1: Unstable networks can slow down or break agents
AI agents are distributed by design. The neural networks powering them are massively parallel, with the largest enterprise models requiring thousands of nodes. These nodes need fast, stable, low-latency connections, or model performance drops significantly. Even if your organization doesn’t run its own models and uses a third-party provider, like OpenAI or Anthrophic, you’re still dependent on a stable connection between your application and the provider.
Not only does the model itself create potential risks, but so do the applications supporting it. Organizations often use retrieval-augmented generation (RAG) to add third-party data sources, like company wikis and knowledge bases, but these systems need separate distributed systems to process and store data. Many large language model (LLM) providers also offer multi-agent (or handoff) orchestration, where one model delegates tasks to other models better suited for them. For instance, a text-based model can’t generate an image, but it can call another model that specializes in image generation.
The common thread in all of these is that they rely on fast, stable, low-latency network connections between many different endpoints. A single latency spike or outage at any point in this chain can have cascading effects and cause unexpected or undefined agent behavior. Even small amounts of latency in each individual call could cascade into a much larger problem. If any of these connections fails, your agent might:
- Time out while waiting for a response from a different agent.
- Retry connecting to a vector database in an endless loop, exhausting resources and tokens.
- Fall back on stale data, leading to incorrect or irrelevant conclusions.
Solution: Simulate real-world network failures to test error handling
How do you determine how your agent will respond if a key network connection fails? By proactively simulating a failure in that connection.
Gremlin’s blackhole experiment tests this by dropping packets sent between hosts, containers, and applications. It drops all network traffic by default, but you can fine-tune it to only target specific hostnames, IP addresses, or CIDR blocks. For example, how does your agent respond when it can’t reach your RAG database, or when it can’t delegate tasks to another model? To find out, run a blackhole experiment that drops traffic to your database or model endpoint(s), run your queries, and use its output to determine whether your agent handled the outage successfully.
Gremlin provides other network experiments including packet loss, latency, and DNS. Packet loss drops (or optionally corrupts) a percentage of packets between your agent and its dependency, letting you test its retry and fallback logic. Does your agent fail gracefully after a certain number of tries, or will it keep trying to contact dependencies indefinitely? Latency slows packets between your agent and dependencies, and can uncover broken timeouts. And DNS shows you what happens when your agent can’t resolve domains: does it fall back to cached queries, does it use the host’s cached queries, or does it fail?
2: Tool and function calls expose your agent to dependency failures
While finding and testing dependencies is important in any application, AI agents magnify the problem. When answering prompts, AI agents can use tool (or function) calling to perform any number of functions, including:
- Searching: when an agent can’t form an answer from its training data, it can turn to search engines for up-to-date info.
- RAG: vector databases provide important context to agents that isn’t present in its training data, like internal company data or file uploads.
- Calling other agents: services like Amazon Bedrock can split and orchestrate tasks across multiple agents, leveraging each model’s specialties instead of using one “jack-of-all-trades” model.
- Calling third-party service providers and APIs: agents can interact with observability tools, databases, incident management tools, reliability testing tools, and more.
A failure in any one of these services might not stop the agent from completing its task, but it will change its output and could result in silent errors.
Solution: Identify and test your agent’s dependency chain
Gremlin automatically identifies dependencies that your services communicate with. It uses this to create a dynamic list that always remains up-to-date, even as your agent connects to different third-party services.
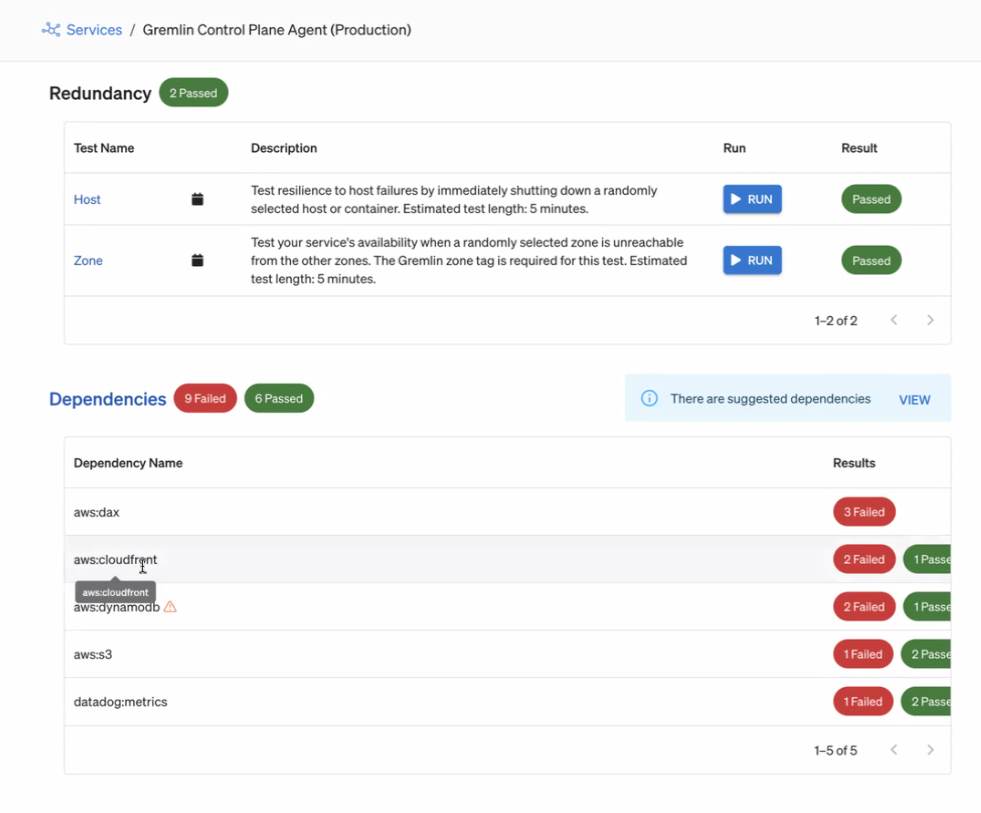
Gremlin also creates a default set of reliability tests to run on each dependency:
- Blackhole simulates a dependency outage.
- Latency adds a delay in network traffic between your agent and the dependency.
- Certificate Expiry tests the dependency’s TLS certificate chain for soon-to-expire certificates.
Running these tests helps answer:
- Does my agent handle timeouts and unavailable services gracefully?
- Does my agent continuously retry connecting, potentially exhausting tokens, or does it eventually back off?
- If my agent backs off, how does this affect its final output? Does it note the error and continue processing, fail silently, or fall back to old data?
- Do any of my dependencies have TLS certificates that are expiring soon, and could this cause problems for my agent?
3: Non-deterministic behaviors make traditional testing ineffective
Unlike traditional code, feeding the same input to an AI agent can yield different outputs. AI models have a degree of randomness represented in part by their temperature. While this enables AI models to answer prompts creatively, it also creates unique reliability challenges:
- Traditional testing methods that rely on fixed or expected outputs no longer work.
- Debugging failures or bad responses is significantly harder.
- Understanding the model’s state is effectively impossible.
The challenge is finding a testing methodology that accounts for this non-deterministic behavior.
Solution: Test regularly to ensure your AI agents stay reliable
It’s not enough to run reliability tests on your agents once, but regularly and consistently. AI agents exist in an ever-changing landscape: model clusters scale up, your organization might connect new tools, and new functionality can introduce new third-party dependencies. Regular testing ensures that you have an accurate, ongoing measure of your agent’s reliability.
We recommend adding Health Checks to monitor key metrics and safely halt testing if there are unexpected impacts on your agent or service. Once those are in place, schedule weekly reliability tests to run automatically. Running repeat experiments lets you track reliability improvements over time, monitor your agent’s dependency chain, and identify reliability risks or areas that need additional testing. You can prioritize reliability work based on actual measured risk, make a business case for infrastructure investments, and prove that you’re meeting compliance requirements.
AI needs proactive reliability
AI agents are already taking actions, making decisions, and interacting with critical systems on behalf of organizations. Even if they aren’t part of your critical path, failures can still have large-scale impacts. The question isn’t whether agents and the systems they rely on will eventually fail, but how well they can survive failures.
Gremlin lets you get ahead of these failures by proactively mapping dependencies, simulating failure modes to find reliability risks, and testing regularly to track changes in your agent’s resilience.
Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALInsights to keep AI applications reliable
AI has become a massive investment for companies, but how do you keep AI applications reliable? Check out these insights from Gremlin, Nobl9, and Pagerduty to find out!


AI has become a massive investment for companies, but how do you keep AI applications reliable? Check out these insights from Gremlin, Nobl9, and Pagerduty to find out!
Read moreHow to make your AI-as-a-Service more resilient
Getting an AI-powered service up and running is hard; keeping it running is even harder. Read how AI-as-a-service systems can fail and how Gremlin makes them reliable.


Getting an AI-powered service up and running is hard; keeping it running is even harder. Read how AI-as-a-service systems can fail and how Gremlin makes them reliable.
Read moreEnsuring your AI systems can scale to meet demand
Demand for AI services is ever-increasing. Are your systems prepared? This blog teaches you how to prepare for sudden demand surges.

Demand for AI services is ever-increasing. Are your systems prepared? This blog teaches you how to prepare for sudden demand surges.
Read more