
In January of 2020, an entire availability zone (AZ) in AWS’ Sydney region suddenly went dark. Multiple facilities lost power, preventing customers from accessing EC2 instances and Elastic Block Storage (EBS) volumes. Customers who didn’t have backup infrastructure in another zone had to wait nearly 8 hours before service was restored, and even then, some EBS volumes couldn’t be recovered.
Major cloud provider outages are rare, but they happen nonetheless. How do you avoid outages like these, especially if they affect an entire datacenter? In this blog, we’ll explain what zone redundancy is, and how you can safely verify that your systems are zone redundant without having to wait for a major outage to happen first.
What is zone redundancy?
A service is zone redundant when it can continue serving requests even when its primary availability zone fails. In cloud computing parlance, an availability zone (AZ) is made up of one or more isolated datacenters that can operate independently of other AZs. This helps to isolate failures, but this also means that an AZ is a single point of failure. If you deploy all of your infrastructure to a single AZ and that AZ goes down, so do your services.
Why should you be zone redundant?
While AZ failures are infrequent, they’re not unheard of. AZs can catch on fire, flood, lose power, or be misconfigured by engineers. When incidents like these happen, services running in the AZ go offline until the problem is resolved, and possibly long after a fix has been deployed. Running your infrastructure across two AZs reduces the risk of your services becoming unavailable because of this. It’s especially important for critical services like banking, healthcare, and government, where downtime can have heavy financial or public safety costs.
Major cloud providers like AWS, Azure, and GCP put significant resources into providing high resiliency, but even they can’t take full responsibility. AWS explains this in detail in their Shared Responsibility Model for Resiliency, which says customers are responsible for “deploying [workloads] across multiple locations (such as AWS Availabiliity Zones).” Cloud platforms like AWS have tools to help you build zone-redundant infrastructure, but it’s up to you to use them effectively and run tests to validate that your configuration works.
How to implement zone redundancy
So what does it take to become zone redundant? Generally speaking, zone redundancy requires:
- Your services must be replicated in at least two AZs. This doesn’t necessarily mean your infrastructure must be replicated 1–1: you can run services at a lower capacity in the second AZ, as long as they can scale up fast enough to meet a sudden surge in demand.
- Data must be replicated between AZs to avoid data loss and service interruptions. Some data hosting services like Amazon Elastic File System (EFS) natively support multi-AZ redundancy.
- You should have a load balancer, API gateway, or similar service that can direct traffic between AZs. This service also needs a way to monitor the availability of each AZ and detect if one is unhealthy or unavailable.
The process for becoming zone redundant is beyond the scope of this blog, but for guidance on what it might look like for your team, check out our blog on deploying a multi-AZ Kubernetes cluster for high availability.
How to test zone redundancy with Gremlin
The best way to test whether your systems are zone-redundant is to recreate a zone failure and observe your services to ensure that they keep working as expected. This is the most effective way of testing and demonstrating redundancy as it most closely represents real-world conditions. However, cloud providers aren’t thrilled about the idea of taking entire datacenters offline, so there needs to be a smarter, safer, and more controlled way to do this.
Gremlin offers a way to do this called Scenarios. Scenarios are workflows for creating failure modes such as network outages, latency, high resource consumption, and container failures. Gremlin comes with over 30 pre-built “Recommended Scenarios” based on common failure modes and industry best practices (you can, of course, create your own). For this blog, we’ll look at the “Redundancy: Zone” Scenario.
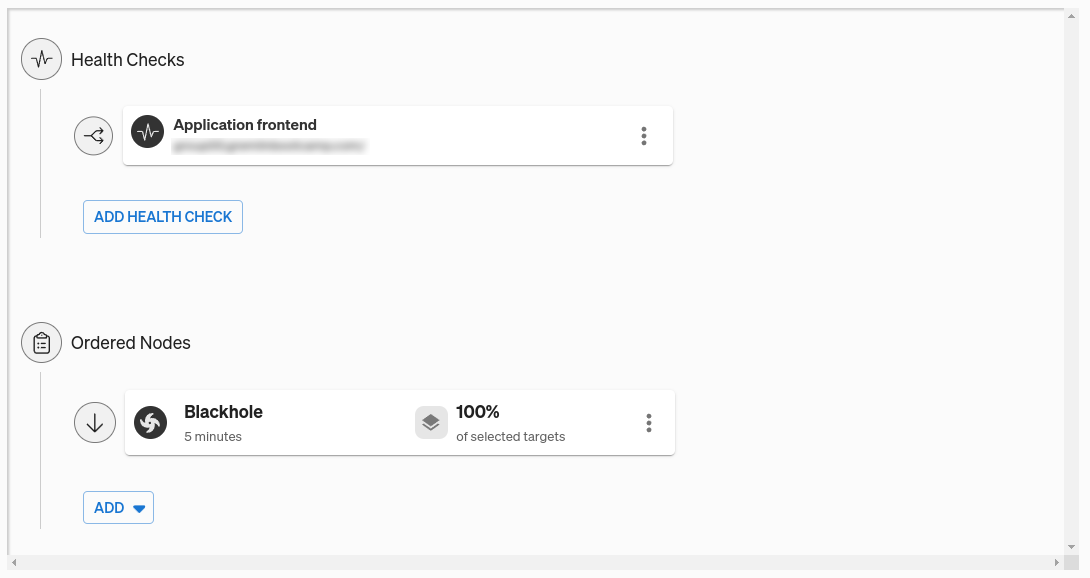
To run this Scenario, we first need to add a Health Check. A Health Check is an endpoint that Gremlin periodically checks during the Scenario to determine whether our application is in a healthy state. If the endpoint becomes unavailable, takes too long to respond, or reports an error, Gremlin will immediately halt and revert the Scenario, returning the system to normal. Gremlin natively integrates with a number of observability tools, so as a best practice, we recommend using your existing monitors or alerts for your Health Checks. If your application has a public-facing URL, you can also use that as a simple uptime/availability check.

The next step in the Scenario is to run a blackhole experiment for five minutes. Experiments are steps in the Scenario where we inject a fault into the target system(s), and blackhole experiments are designed to drop network traffic to the target.
Blackhole experiments have the dual benefit of being easy to use and easy to revert if needed. We could use a shutdown experiment to turn off or reboot the systems, but unless we know for certain that our systems will restart and come back online, this could leave our systems unrecoverable until we manually intervene. With a blackhole experiment, the system returns to normal immediately after the experiment ends.
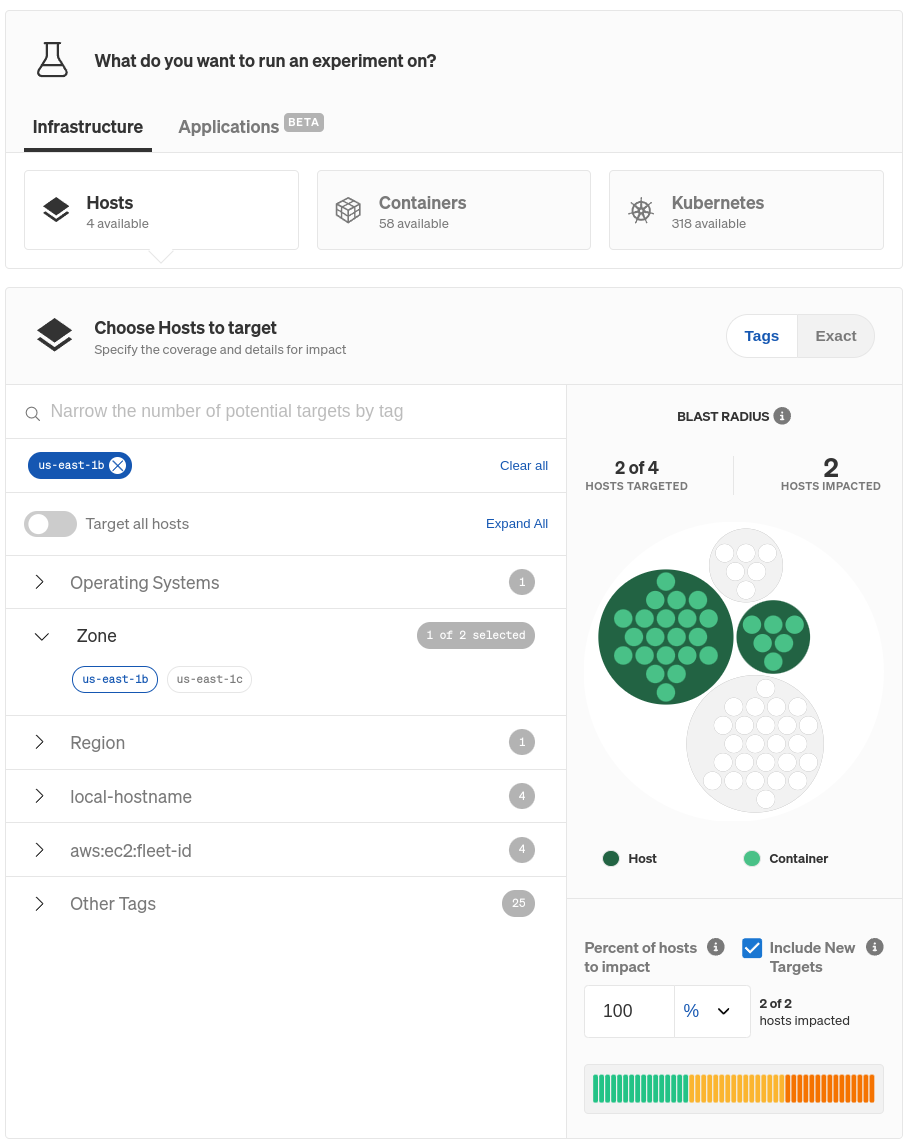
We currently don’t have any targets selected, but we can change that by clicking on the hamburger menu next to the blackhole experiment node, then Edit. Here, we can select the targets for this experiment. Gremlin makes it super simple to target an entire zone: we can just scroll down to Choose Hosts to target (this also works for containers), expand Zone, then select the specific AZ we want to block traffic to. In this example, we chose us-east-1b, implying our systems will fail over to the other AZ (us-east-1c). Gremlin also highlights the impacted systems so we can visually confirm these are the ones we want to impact.
For the Health Check, we’ll use one we've already created. You can learn more about Health Checks, how they work, and which observability tools Gremlin supports in our documentation.
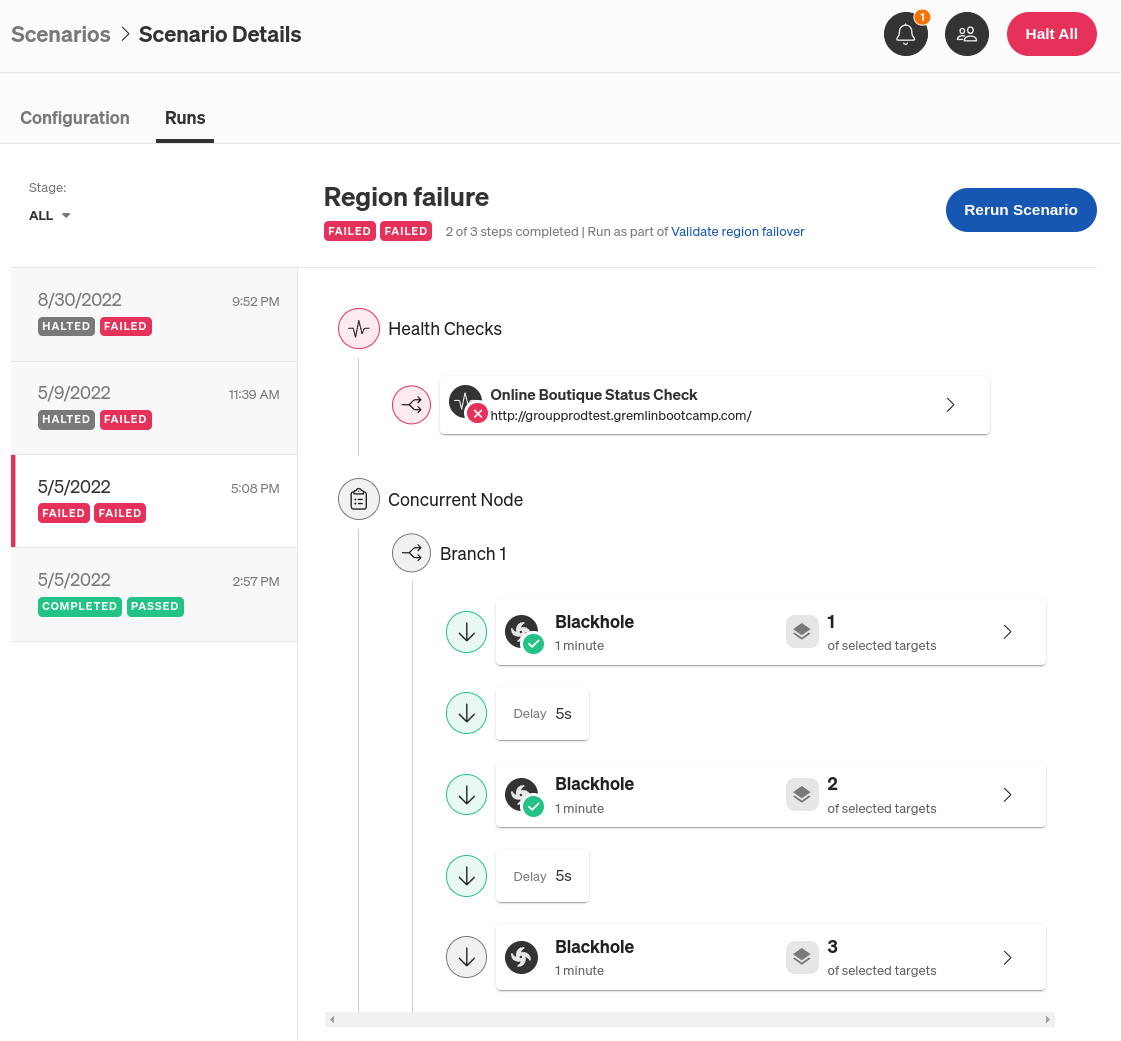
Once we’ve added our Health Check and saved the Scenario, we can run it. Clicking “Run” triggers the blackhole experiment, which drops network traffic to all of the nodes running on us-east-1b (except for traffic to the Gremlin API). While the Scenario is active, Gremlin runs the Health Check every 10 seconds.
So, what do we expect to happen? Assuming we have proper zone redundancy in place, and our load balancer detects the failed connection to us-east-1b, the Scenario should run to completion and our Health Check shouldn’t raise any errors. This means that traffic is being redirected properly and users can still access our web application without any significant slowdowns or errors. However, if the application takes too long to respond or returns an error, or the Scenario can’t complete, then there’s likely a deeper issue that we need to look into.
What other scenarios should I be testing for?
Zone redundancy is a common use case for running Scenarios, but it’s not the only one. Gremlin comes with over 30 pre-built Recommended Scenarios for testing everything from zone redundancy, to certificate expiration, to auto-scaling. This is just the first in a series of blog posts on each Recommended Scenario, so stay tuned for more.
In the meantime, if you’re interested in testing your own services, you can sign up for a free 30-day Gremlin trial.
Length:
10 minutes
Experiment(s):
Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALBest Practices for Testing Zone Redundancy
Gremlin Principal Software Engineer Sam Rossoff shares key best practices and strategies for effectively testing zone redundancy.


Gremlin Principal Software Engineer Sam Rossoff shares key best practices and strategies for effectively testing zone redundancy.
Read moreHow to deploy a multi-availability zone Kubernetes cluster for High Availability
Many cloud infrastructure providers make deploying services as easy as a few clicks. However, making those services high availability (HA) is a different story. What happens to your service if your cloud provider has an Availability Zone (AZ) outage? Will your application still work, and more importantly, can you prove it will still work?


Many cloud infrastructure providers make deploying services as easy as a few clicks. However, making those services high availability (HA) is a different story. What happens to your service if your cloud provider has an Availability Zone (AZ) outage? Will your application still work, and more importantly, can you prove it will still work?
Read more