Zero-click risk detection
Uncover critical reliability risks as soon as you deploy your service, without running a single test.
Hundreds of finance, retail, and technology organizations worldwide trust Gremlin












Comprehensive and automatic reliability risk detection
Stay one step ahead of reliability risks by detecting them before they impact your customers. With Detected Risks, Gremlin automatically monitors the services running in your environment for potential failure modes—without requiring any active testing.
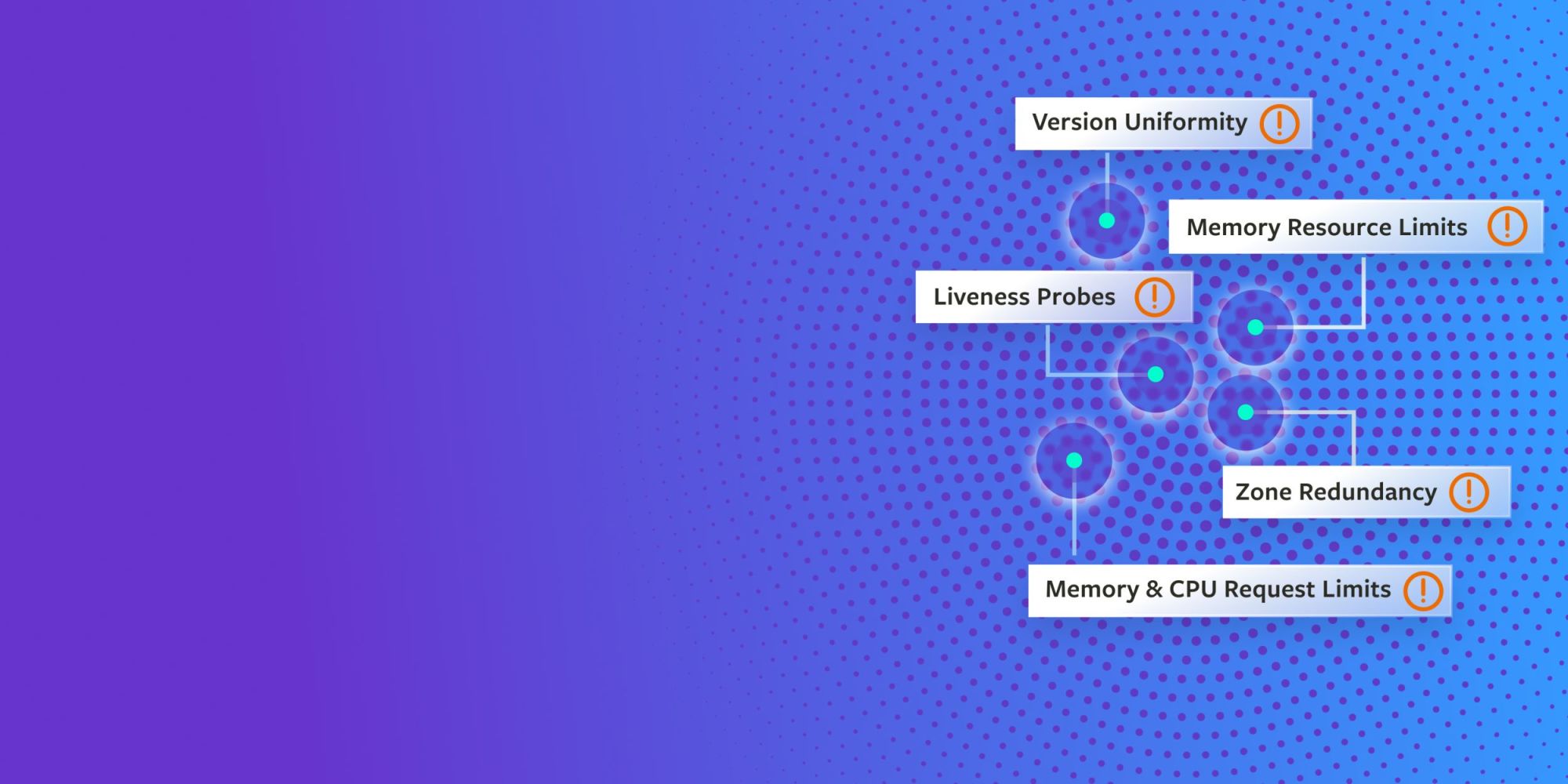
What is a reliability risk?
A reliability risk is anything that jeopardizes a system’s ability to work as expected, such as missing autoscaling rules, limited or no redundancy, and no automatic health checks or liveness probes. Risks have the potential to become incidents or outages in production. Gremlin helps teams proactively find and fix these risks before they can impact your customers.
What risks can Gremlin detect for you?
Reveal hidden reliability risks
Modern systems have countless moving parts. The potential for failure is significant and increases as teams move to distributed cloud-native platforms.
Gremlin continuously monitors your changing environments for common reliability risks, such as missing autoscaling rules, undefined resource limits, and non-redundant services. It then surfaces these risks in an easy-to-understand way, so you can see what areas require your attention.
Surface regressions and recurring issues
As systems change, the chance of a regression grows. Gremlin’s fully automated risk detection processes capture risks as soon as they appear in your environment, letting you know immediately if something’s wrong.
Gremlin tracks these risks over time and also presents them as a team-wide report so you can identify risks across all of your services at once. And as Gremlin’s risk library continues to grow, you’ll get more insights into how reliable your services are—all without having to run a single Chaos Engineering experiment.
Build confidence in your system's resiliency
Engineering teams need to know that their systems can withstand any type of fault at any time. Gremlin helps you understand how your systems behave under any condition, not just ideal conditions.
Environments change over time, especially as systems scale and engineers push new code. Gremlin helps you stay ahead of changing systems and configuration drift with automated, repeated experiments. Confidently push to production knowing that your changes won’t introduce new reliability risks.
Shift from observing to improving
Gremlin enables teams to proactively improve reliability at every stage of maturity.

Robust, customizable chaos tests to safely replicate any incident scenario.

Pre-built test suite to cover the most common reliability risks. Get started in minutes.

Standardized scoring tools to identify and prioritize risks, and build reliability programs.