
Legendary race car driver Carroll Smith once said, "until we have established reliability, there is no sense at all in wasting time trying to make the thing go faster." Even though he was referring to cars, the same goes for technology: no amount of code optimization or new features can replace stable systems. Unfortunately, much like race cars, it's hard to know that a system is unreliable until it blows a tire, the brakes stop working, or the steering wheel comes off the column. By that point, it's too late: you're panicking, you and other engineers are scrambling to fix the issue, and your users are angry.
The best way to prevent an incident like this is to prepare for it by testing your systems before they go into production. This means running tests explicitly designed to validate a system's reliability—in other words, how well you can trust it to remain available under less than ideal conditions. The challenge is knowing how to run these tests and which ones to run in the first place.
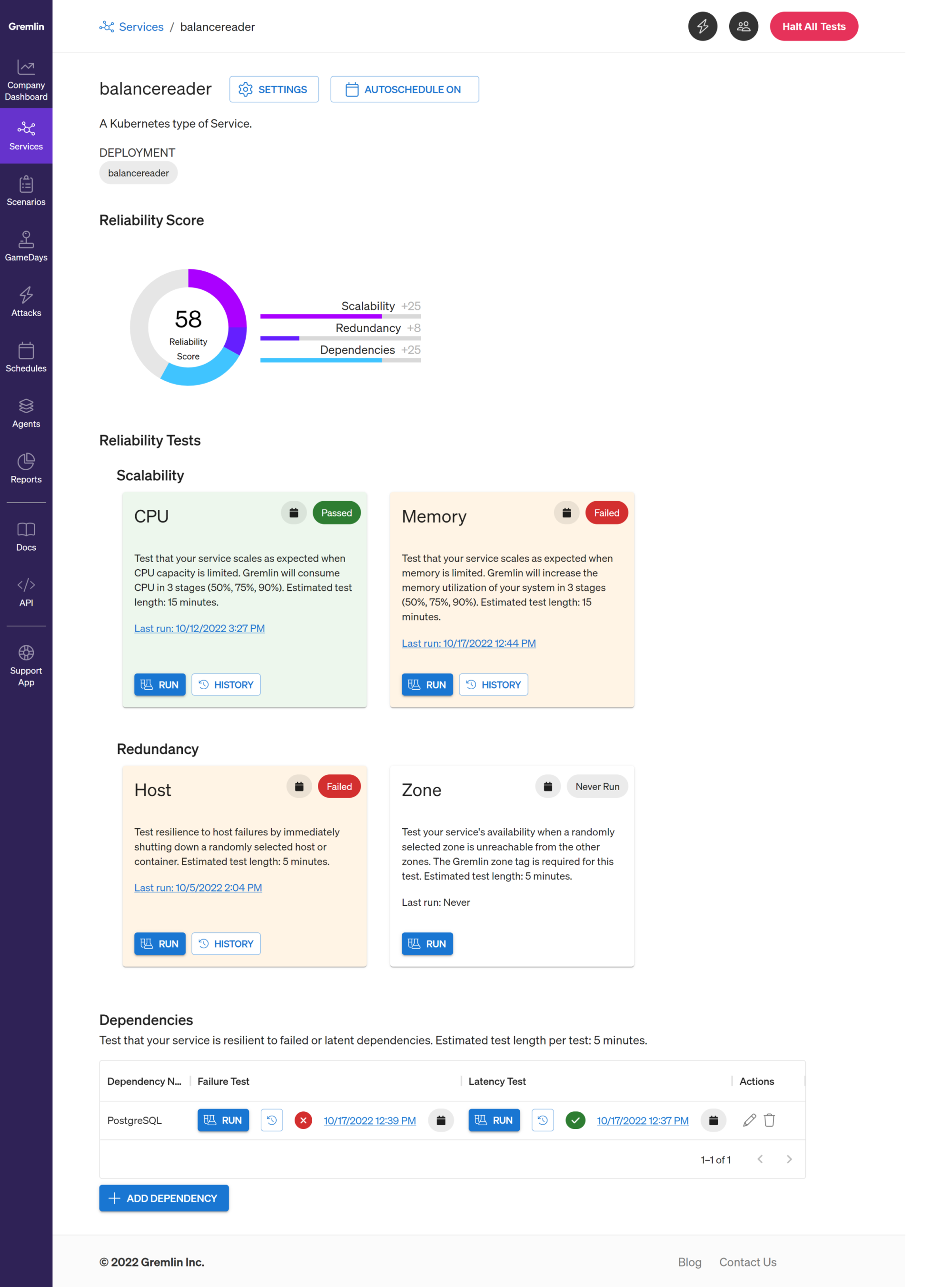
Gremlin provides a set of pre-built reliability tests that you can run on your services. We designed these tests to validate resilience against common failure modes and ensure your services met best practices for reliability. In this blog, we explain why you should run these tests and how they can paint a picture of the reliability of your services.
Testing the reliability of cloud-native distributed systems
For modern distributed systems to be considered reliable, they generally need to have these capabilities:
- Automatically scale in response to demand to maintain high performance even under heavy traffic.
- Have at least one redundant system ready to bring services back online if they fail.
- Workaround or withstand being disconnected from other services.
- Workaround or withstand poor or unstable network performance (i.e., latency).
In other words, our systems need to be scalable, redundant, resilient to network outages, and able to tolerate latency.
These are also the categories Gremlin uses to group reliability tests. For example, the Scalability category includes separate tests for CPU and Memory. After all, it's just as crucial for services to scale when RAM usage is high as when CPU usage is high. Likewise, the Redundancy category includes separate tests for host outages and availability zone outages. Your service should be just as capable of failing over to a healthy zone as a healthy host.

Why did we choose these tests?
When deciding which reliability tests to include, we looked at the best practices teams adopt—and the common failure modes they experience—when working with modern distributed cloud-native systems.
For example, AWS Well-Architected is a framework designed by AWS to help its customers build resilient and scalable systems on AWS. It consists of six pillars that each tackle a specific challenge: operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability. Successfully implementing these pillars will better optimize your workloads for AWS, but the general principles can apply to any large-scale distributed system.
Learn how to use the Well-Architected Framework to make the best architectural decisions based on your business needs by watching our webinar, presented in partnership with Amazon Web Services: Continuous validation of the Well-Architected Framework.
Gremlin has years of experience working with some of the world's largest enterprises across many different industries. This gives us a unique look into the challenges that teams face when testing reliability at an enterprise scale, and we used this insight when designing our tests. We may also add more tests over time as cloud-native organizations' needs and expectations change along with the technology landscape.
What happens if we don't run regular reliability tests?
Like traditional QA tests, reliability tests catch defects before they make their way into production. Gremlin tests for failure modes common to modern distributed systems, including:
- Are my services redundant enough to withstand one or more hosts failing?
- Can I scale automatically to meet increasing demand?
- Is my service resilient to slow or failed dependencies?
We must regularly test these assumptions or risk something unexpected and undesired impacting our customers. And much like regression testing, regular reliability testing ensures that future changes we make to our code and infrastructure don't introduce bugs or uncover old ones.
Here are some of the more significant impacts of not running regular reliability tests.
Our systems will scale less efficiently
Scaling is an inherent benefit of distributed systems and cloud-native applications. One of the main draws of cloud platforms like AWS, Azure, and GCP is that they support automatic scaling. Once demand reaches a certain threshold, the platform can automatically provision and deploy new systems to add capacity and lower your overall resource saturation. If you don't have autoscaling, you'll either need to monitor your systems' usage continually and manually deploy new systems when required or risk exhausting all available resources once demand reaches too high of a level. Both situations can cost you time, money, effort, or even downtime due to crashes.
We'll be more susceptible to zone and region failures
The unfortunate reality about complex systems is that they can fail anytime and for any reason. Cloud providers work hard to ensure their systems are reliable—or at the very least, can failover quickly—but it's up to us as engineers to ensure our services and applications can do the same. Some scenarios could negatively impact us in a way that a cloud provider can't immediately resolve, such as a zone or region outage.
The great thing about today's distributed systems is that redundancy can be mostly automated. For example, Kubernetes lets you easily replicate individual services using Deployments, and cloud compute platforms like Amazon EC2 let you set up completely redundant availability zones with automatic load balancing. This way, your systems and services will remain resilient even during large-scale outages.
Network outages will have a greater impact on our systems
Modern applications often depend on external dependencies. These can include:
- Cloud provider services like load balancers, databases, and message queues.
- Services that our team maintains.
- Services managed by other teams in our organization.
Imagine that we have a web service that connects to an external database. Now imagine that a network problem or system crash causes our service to disconnect from the database. How will our service respond? Does it recognize that the database is unavailable and return an error message? Does it keep retrying the connection and eventually give up? Or does it not recognize the disconnection and time out or crash? These are all important to know, as it tells us how our service will behave if the same scenario happens in production.
Our services may be more susceptible to latency
Microservice-based applications are much more susceptible to latency—delays in network traffic—than monolithic applications. This is especially true for services that send traffic over the Internet, where it may travel hundreds of miles through dozens of routers, switches, gateways, and firewalls. These delays are usually minor (often only a few milliseconds), but when added up for each network packet, they can quickly make your application seem slow or sluggish.
This is one of the main drawbacks of distributed systems like Kubernetes. In Kubernetes, cross-service communication happens almost exclusively over the network. Even if we deploy a Kubernetes cluster on a high-speed network, any change in network saturation or reliability can significantly impact our service. This is why we must proactively test our service's ability to tolerate different latency levels, especially when communicating with critical dependencies like databases and file stores.
How to start running reliability tests
Gremlin makes it easy to run reliability tests on your services. Simply define your service, connect your Health Checks, find the test you want to run, then click run. Gremlin provides the four reliability tests mentioned in this blog and more. Because it automatically detects your service's dependencies, you can quickly and easily test for dependency failures by simulating outages or adding latency. While a test is running, Gremlin continuously monitors your service via its Health Checks to ensure it's available, responsive, healthy, and stable.
If you're ready to start testing and improving the reliability of your services, contact us for a demo.

Gremlin's automated reliability platform empowers you to find and fix availability risks before they impact your users. Start finding hidden risks in your systems with a free 30 day trial.
sTART YOUR TRIALIntroducing Custom Reliability Test Suites, Scoring and Dashboards
Last year, we released Reliability Management, a combination of pre-built reliability tests and scoring to give you a consistent way to define, test, and measure progress toward reliability standards across your organization.


Last year, we released Reliability Management, a combination of pre-built reliability tests and scoring to give you a consistent way to define, test, and measure progress toward reliability standards across your organization.
Read moreTreat reliability risks like security vulnerabilities by scanning and testing for them
Finding, prioritizing, and mitigating security vulnerabilities is an essential part of running software. We’ve all recognized that vulnerabilities exist and that new ones are introduced on a regular basis, so we make sure that we check for and remediate them on a regular basis.


Finding, prioritizing, and mitigating security vulnerabilities is an essential part of running software. We’ve all recognized that vulnerabilities exist and that new ones are introduced on a regular basis, so we make sure that we check for and remediate them on a regular basis.
Read more